第 11 章强化学习(强化学习;RL)
推荐阅读:【算法】【算法索引】(https://jb243.github.io/pages/1278)
1. 概述
2. 马尔可夫链
3. 马尔可夫决策过程
4. 一般决策过程
a. 随机控制理论
1.概述
⑴ 定义
① 监督学习
○ 数据:(x, y)(其中 x 是特征,y 是标签)
○ 目标:计算映射函数 x → y
② 无监督学习
○ 数据:x(其中x是一个特征,没有标签)
○ 目标:了解x的底层结构
③ 强化学习
○ 数据:(s, a, r, s’)(其中 s 是状态,a 是动作,r 是奖励,s’ 是下一个状态)
○ 目标:在多个时间步长内最大化总奖励
⑵【随机控制理论】(https://jb243.github.io/pages/895)
① 要素 1. 状态
② 要素2. 奖励
○ 定义:状态的变化。
○ 价值函数: 未来奖励的预期价值,表示为终生价值(VLT)。
○ 公式:对于状态 s,政策 π 和将未来值调整为现值的贴现因子 γ。
○ 通过评估状态的好坏,为选择行动提供依据。
③ 要素 3. 动作
④ 要素 4. 政策
○ 定义:代理人的行为;将状态作为输入并输出操作的映射。
○ 决策过程:决策问题的一般框架,其中状态、行动和奖励在一个过程中展开。
○ 类型 1: 确定性策略
○ 类型 2: 随机策略
○ 原因一: 在学习中,最优行为是未知的,因此需要探索。
○ 原因 2: 最佳情况本身可能是随机的(例如,石头剪刀布,或者对手利用决定论)。
⑤ 要素 5. 型号
○ 定义:环境的行为/动态。
○ 给定一个状态和一个动作,模型决定下一个状态和奖励。
○ 请注意无模型方法和基于模型方法之间的区别。
⑶ 特点:区别于监督学习和无监督学习
① 隐式获得正确答案:以奖励的形式提供
② 需要考虑与环境的交互:延迟反馈可能是一个问题
③ 之前的决定影响未来的互动
④主动收集信息:强化学习包括获取数据的过程
2.马尔可夫链
⑴ 概述
①定义:未来状态仅取决于当前状态而不取决于过去状态的系统
② 马尔可夫链是指状态空间有限或可数无限的马尔可夫过程。
③ 引理1. Chapman-Kolmogorov 分解
④ 引理2. 线性状态空间模型
⑵【图论】(https://jb243.github.io/pages/616)
① 强连通(= 不可约):图中任意节点 i 都可以到达任意其他节点 j 的状态
② 周期:返回节点 i 的所有路径的最大公约数
○ 示例:如果两个节点 A 和 B 用两条边连接为 A=B,则每个节点的周期为 2
③ 非周期:当所有节点的周期为1时» ○ 非周期 ⊂ 不可约
○ 示例:如果每个节点都有返回自身的步行,则它是非周期的
④ 平稳状态:如果 Pr(xn xn-1) 与 n 无关,则马尔可夫过程是平稳的(时不变)
⑤ 常规
○ 正则 ⊂ 不可约
○ 如果存在一个自然数 k,使得转移矩阵 M^k 的 k 次方的所有元素均为正(即非零)
⑥ 引理1. Perron-Frobenius 定理
⑦ 引理2. 【李雅普诺夫方程】(https://jb243.github.io/pages/895)
⑧ 引理3. 贝尔曼方程
⑵ 类型1. 二态马尔可夫链
图 1. 二尺度马尔可夫链
① M:一步引起状态转换的变换
② Mn:n步引起状态转换的变换
③稳态向量:满足Mq = q的向量q,即特征值为1的特征向量
⑶ 类型2. HMM(隐马尔可夫模型)
① χ = {Xi} 是马尔可夫过程,Yi = phi(Xi) (其中 phi 是确定性函数),则 y = {Yi} 是隐马尔可夫模型。
② 鲍姆-韦尔奇算法
○ 目的:学习HMM参数
○ 输入:观测数据
○ 输出:HMM的状态转移概率和发射概率
○ 原理:EM(Expectation Maximization)算法的一种
○ 公式
○ Akl: 从状态 k 到 l 的转换次数
○ Ek(b): 状态 k 的观测 b 的发射次数
○ Bk:状态 k 的初始概率
③ 【维特比算法】(http://www.mcb111.org/w06/durbin_book.pdf)
○ 目的:给定 HMM 找到最可能的隐藏状态序列
○ 输入:HMM 参数和观测数据
○ N:可能的隐藏状态数
○ T:观测数据的长度
○ A:状态转移概率,akl = 从状态 k 转移到状态 l 的概率
○ E:发射概率,ek(x) = 在状态 k 下观察到 x 的概率
○ B: 初始状态概率
○ 输出:最可能的状态序列
○ 原理:利用动态规划计算最优路径
○ 步骤1. 初始化
○ bk: 状态 k 的初始概率,P(s0 = k)
○ ek(σ):在状态 k 下观测到第一个观测值 σ 的概率,P(x0 s0 = k)
○ 步骤 2. 递归
○ 计算每个时间步 i = 1, …, T 的先前状态的最大概率
○ 计算反向指针 (ptr),存储最可能的先前状态
»> ○ ptri(l) 用于存储最有可能转变到当前状态 l 的先前状态 k。
○ 步骤 3. 终止
○ 选择最后一个时间步的最高概率
○ 确定最优序列的最后状态
○ vk(i - 1): 状态 k 中前一时间步 i - 1 的最优概率
○ akl:从状态 k 转换到 l 的概率
○ 步骤 4. 回溯
○ 从 i = T, …, 1 开始通过 ptr 数组回溯,恢复最优路径
○ 示例
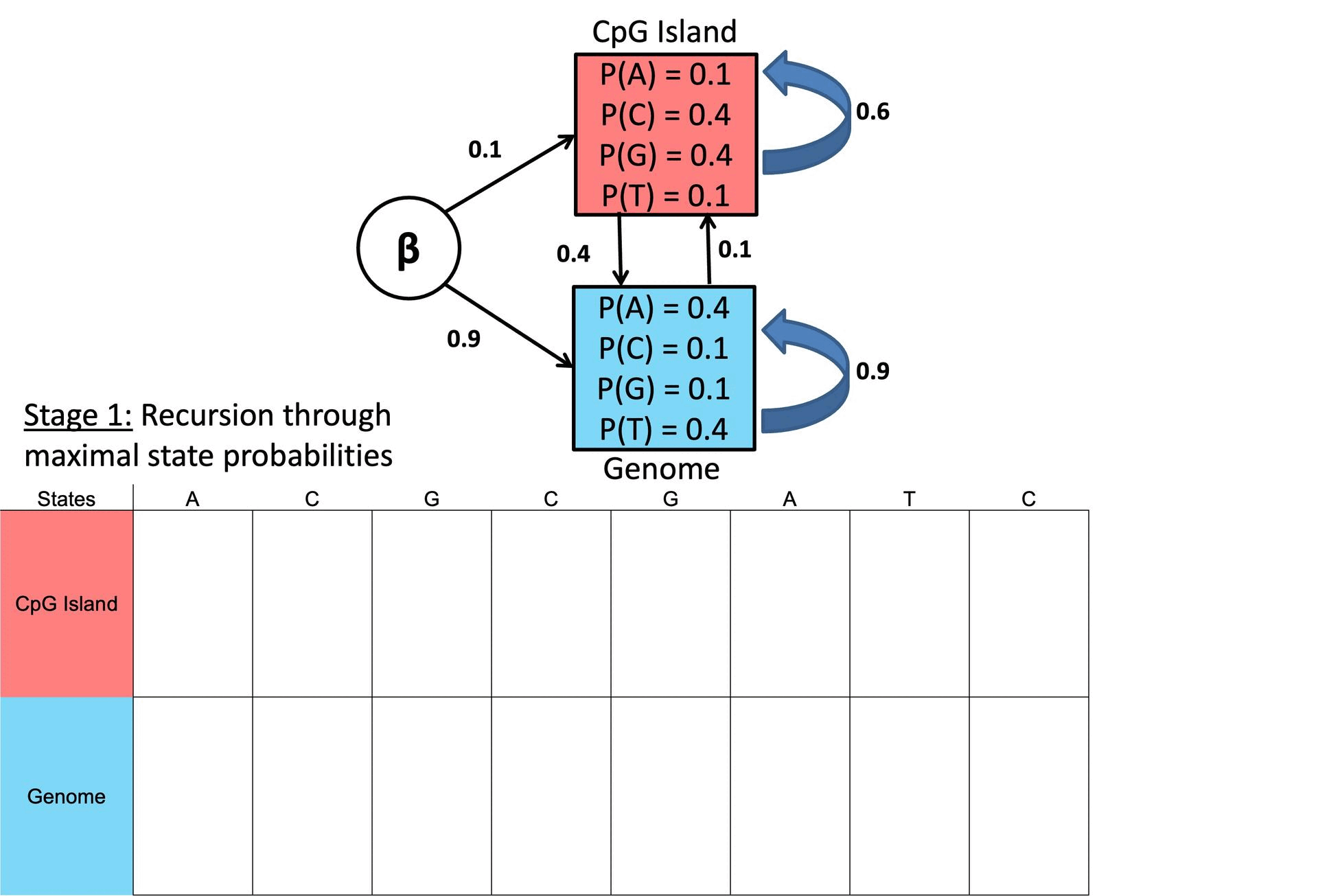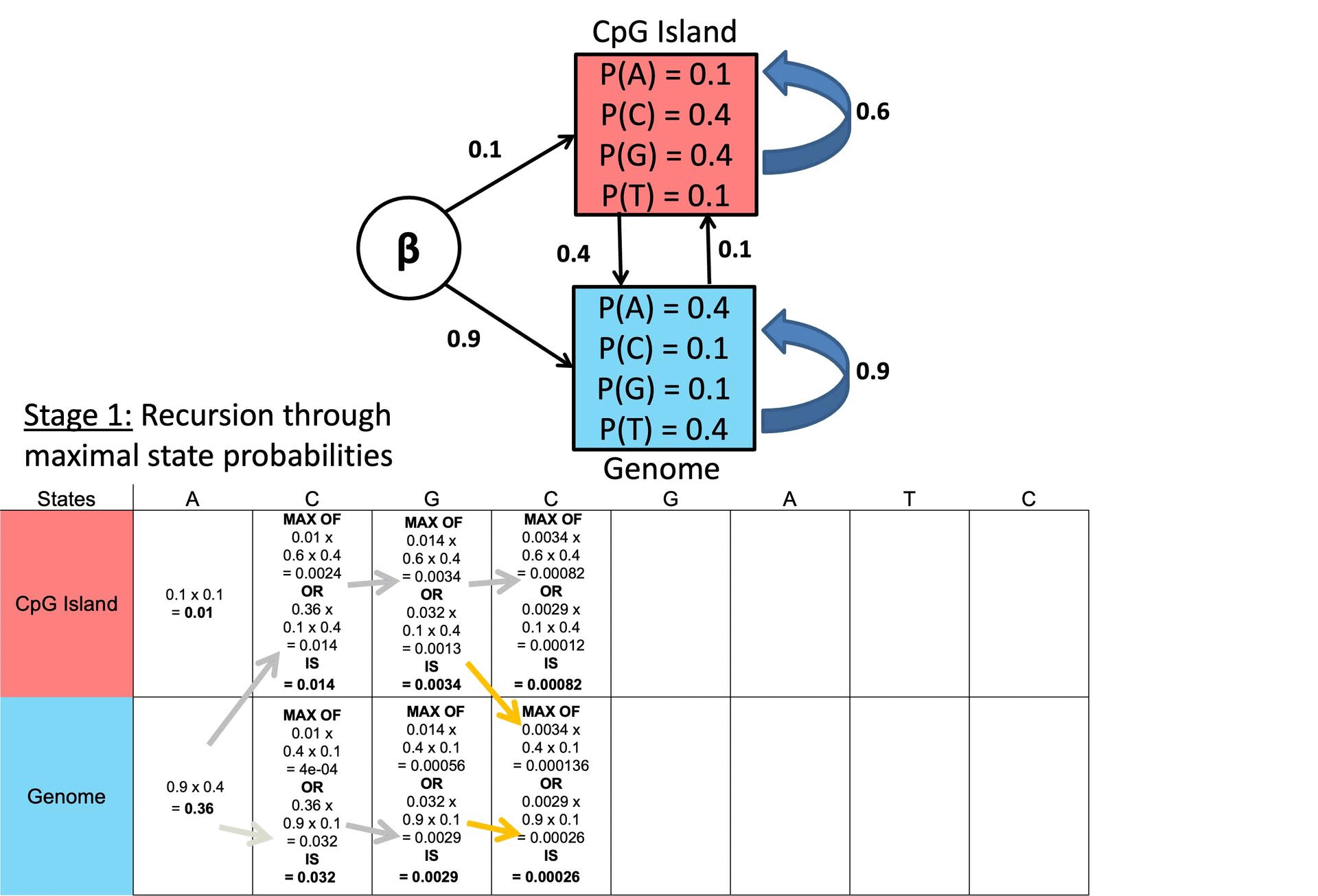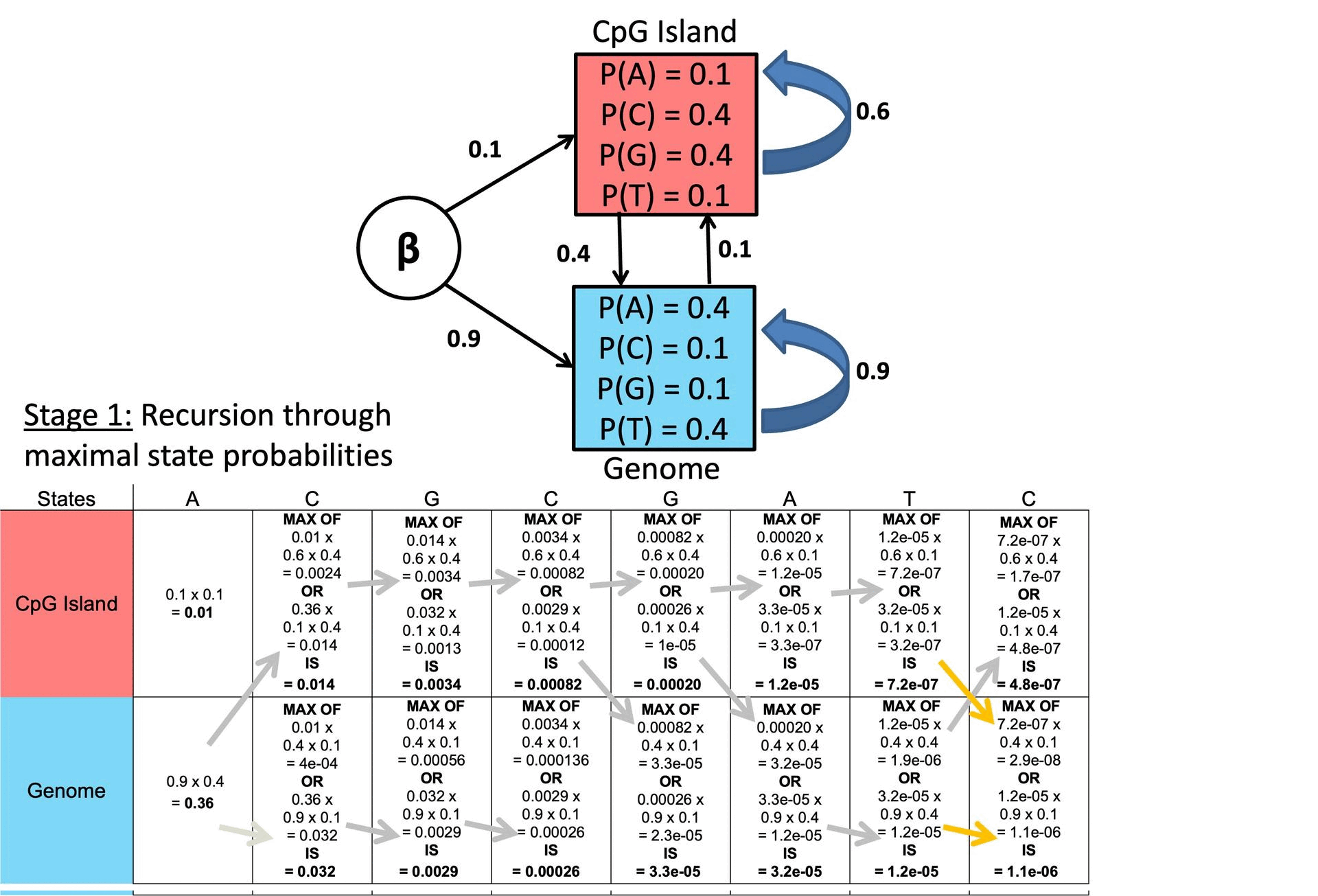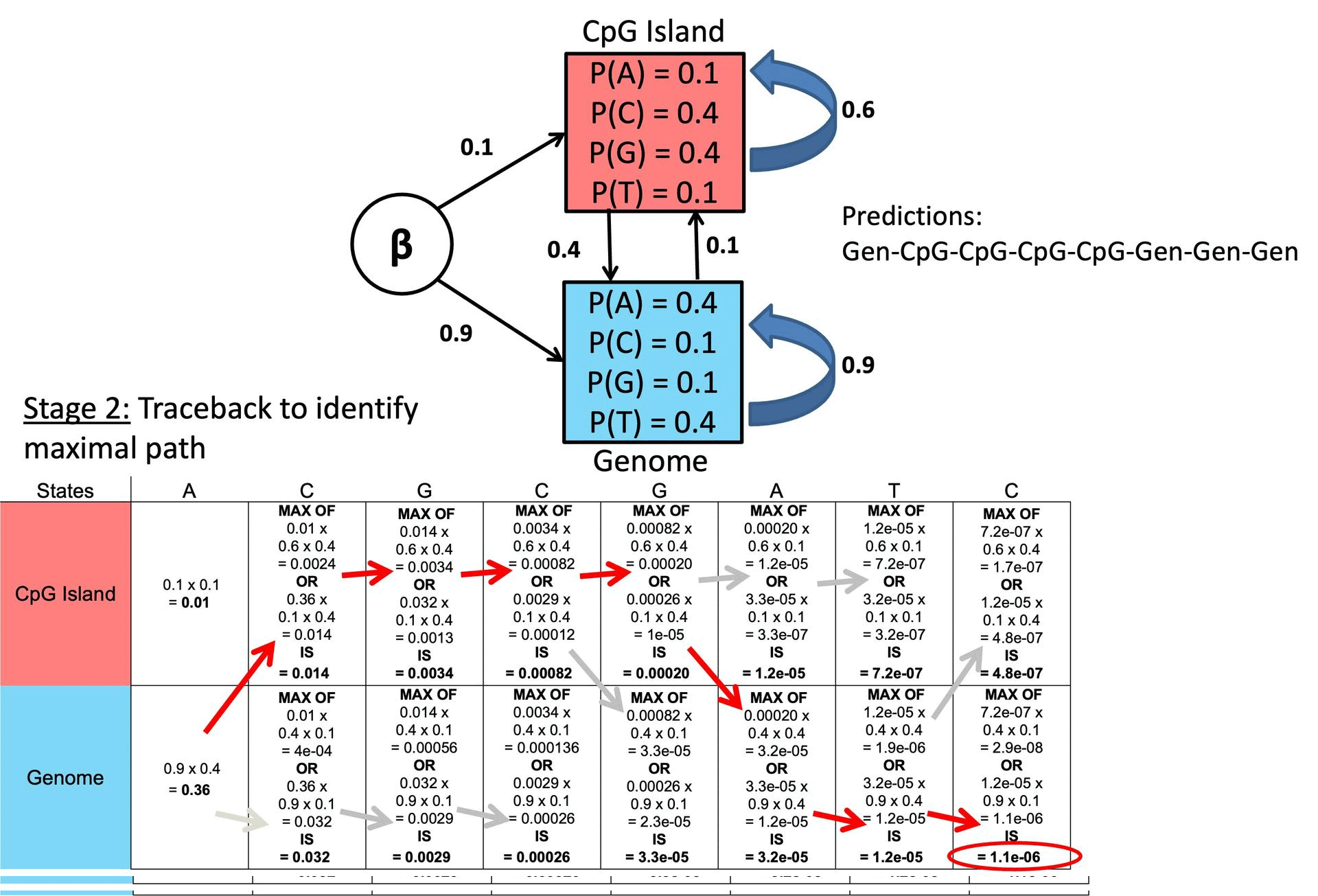
图 2. 维特比算法示例
○ Python 代码
受保护_0
④ 类型1. PSSM:更简单的HMM结构
⑤ 类型 2. Profile HMM:在以下方面优于 PSSM:
○ 轮廓HMM图
图3. 轮廓HMM图
○ M、I、D 分别代表匹配、插入、删除。
○ Mi 可以转换为 Mi+1、Ii 和 Di+1。
○ Ii 可以转换为 Mi+1、Ii 和 Di+1。
○ Di 可以转换为 Mi+1、Ii 和 Di+1。
○ 优点1. 能够对插入和删除进行建模
○ 优点 2. 转换仅限于有效状态遍历之间。
○ 优势 3. 州之间的界限得到更好的界定。
⑸ 类型 3. 马尔可夫链蒙特卡罗 (MCMC)
① 定义:一种从遵循复杂概率分布的马尔可夫链生成样本的方法
② 方法 1. Metropolis-Hastings
○ 从当前状态生成新的候选样本 → 接受或拒绝候选样本 → 如果接受,则转换到新状态
③ 方法2. 吉布斯抽样
④ 方法3. 重要性/拒绝抽样
⑤ 方法4. 可逆跳转MCMC
○ 一般 MCMC 方法,如 方法 1 和 方法 2 从固定维参数空间中的概率分布中采样
○ 可逆跳转 MCMC 在变维参数空间中运行:采样过程中参数数量动态变化
3.马尔可夫决策过程
⑴ 概述
① 定义:未来仅取决于当前状态的决策过程。
○ 在实践中,绝大多数问题设置都可以视为马尔可夫决策过程(MDP)。
② 示意图:对于转换,t+1 处的状态仅由 t 处状态的函数确定。
图 4. MDP 中的代理与环境交互
○ 状态:st ∈ S
○ 动作:at ∈ A
○ 奖励:rt ∈ R(st, at)
○ 策略:at ~ π(· st)» ○ 转换:(st+1, rt+1) ~ P(· st, at)
③最优解V(s)的存在性
○ 前提1. 马尔可夫性质
○ 前提2. 平稳假设
○ 前提 3. 无分配变化
⑵ 类型1. Q-learning
①定义:学习所有状态的价值函数Vπ(s)
○ 转移概率 P(s’ s, a) 未知
○ 奖励函数 R(s, a) 未知
② 方法1.
○ 初始化所有状态/动作对的估计:Q̂(s, a) = 0
○ 初始迭代方案
○ 采取随机行动 a
○ 观察下一个状态 s’ 并从环境中接收 R(s, a)
○ 更新 Q̂(s, a)
○ 后期迭代方案
○ 取 a = arg maxa Q̂(s, a)
○ 观察下一个状态 s’ 并接收 R(s, a)
○ 更新 Q̂(s, a)
○ 随机重启
③ 方法2. ε-贪婪(epsilon-greedy)
○ 初始化所有状态/动作对的估计:Q̂(s, a) = 0
○ 迭代方案
○ 以 1 - ε 的概率,采取 a = arg maxa Q̂(s, a),以 ε 的概率,采取随机行动
○ 观察下一个状态 s’ 并接收 R(s, a)
○ 更新 Q̂(s, a)
○ 在后续迭代中执行随机重启
④ 方法3. DQN(深度Q网络)
○ 定义:利用深度学习实现Q-learning
○ 应用于多种游戏:Atari 2600 (2013) 上的 DQN、AlphaGo (2016) 等。
⑶ 类型2. 政策梯度
①定义:直接学习策略π(s)
② 特点
○ 在 Q-learning 中,状态可以是连续的,但动作必须是离散的
○ 在策略梯度中,状态和动作都可以是连续的
③ 算法
○ 步骤1. 接收帧
○ 步骤2. 前向传播以获得P(action)
○ 步骤 3. 从 P(action) 中采样 a
○ 步骤 4. 玩游戏的其余部分
○ 步骤5. 如果比赛获胜,则在∇θ方向更新
○ 步骤6. 如果比赛输了,则在-∇θ方向更新
⑷ 其他类型
① 深度O-网络(DON)
② A3C(异步优势Actor-Critic)
③遗传算法
④ SARSA(国家-行动-奖励-国家-行动)
4.一般决策过程
⑴ MAB(多臂老虎机)
⑵ UCB
⑶ 汤普森采样
⑷ 【提前停止问题】(https://jb243.github.io/pages/2160#4-early-stopping-problem)
输入:2021.12.13 15:20
更新时间:2024.10.08 22:43