第 8 章聚类算法
推荐文章:【算法】【算法索引】(https://jb243.github.io/pages/1278)
1. 简介
2. 类型1. 无监督分层聚类
3. 类型 2. K-means 聚类
4. 类型 3. 基于密度的聚类
5. 类型4. 混合分布聚类
6. 类型 5. 基于图的聚类
7. 其他聚类算法
1.简介
⑴ 聚类是一个优化问题
① 可变性
○ 变异性可以定义为距离之和或距离平方
○ 距离函数的类型
○ 理由:大而坏比小而坏更糟糕
② 差异
○ 聚类并不是寻找差异性的全局最小值
○ 原因 1. 存在一个简单的解决方案,其中 ∀variability = 0,且聚类数量与样本数量相同
○ 原因 2. 惩罚大集群本身是不公平的:大不一定比小更差
○ 需要约束:簇之间的最小距离、簇的数量等。
⑵ 聚类是一种无监督算法
① 因此,评估聚类算法的性能是困难的,但可以如下评估
② 聚类质量指标
○ 方法 1: 平均轮廓宽度 (ASW)
○ 公式
○ a(i):i到同一簇ci中所有数据点的平均距离
○ b(i):所有簇 c 中,从 i 到另一个簇 c 中的所有数据点的最小平均距离。
○ 簇 c 的轮廓系数 S(c) 是该簇内数据点 s(i) 的平均值。
○ 范围在 -1 和 1 之间。
○ 值越高表示聚类质量越好,意味着聚类内的内聚力越高,聚类之间的分离性越好。
○ 缺点:
○ 得分与簇数成反比。
○ 对于非球形团簇来说是不准确的。
○ 方法 2: Davies-Bouldin 指数 (DBI)
○ 计算过程:
○ 测量每个簇与最相似的其他簇之间的相似度。
○ 将相似度定义为簇间距离与簇内距离的比率。
○ 对所有集群中的这些相似性进行平均以得出 DBI。
○ 值为0或更大;较低的指数表示更好的簇分离。
○ 优点:
○ 受集群数量影响较小。
○ 缺点:»» ○ 如果簇分离不佳或距离变化很大,则可能会变得不准确。
○ 方法 3: 卡林斯基-哈拉巴斯指数 (CHI)
○ 公式:将簇数 k 与数据点数 n 联系起来。
○ 值为0或更大;值越高表示聚类质量越好。
○ 缺点:
○ 索引随着簇大小的增加而减小。
○ 假设方差相对一致。
○ 方法 4: 景观形状指数 (LSI)
○ 方法 5: 异常斑点百分比 (PAS)
○ 值越高表示质量越低:所有斑点中被认为异常(即与其相邻斑点不一致)的斑点的比例。
○ 用于空间转录组学分析。
○ 方法六: VoR(黎曼度量的方差)
○ 值 0 表示全局均匀空间。
○ 方法7: CN(条件号)
○ SVD 后,为最大奇异值与最小奇异值之比,κ = σmax / σmin。
○ 值越大意味着模型越不稳定(病态越严重)。
② 聚类比较指标
○ 方法1: 归一化互信息(NMI)
○ 测量两个集群之间的互信息,并将其标准化以保持集群大小或类数量不变。
○ 范围在 0 和 1 之间。
○ 方法 2: 调整兰德指数 (ARI)
○ 评估两个聚类之间的相似性。
○ 范围在 -1 和 1 之间(完美匹配)。得分 0 表示随机聚类。
○ 兰德指数 (RI)
○ 根据随机聚类结果的预期值进行调整。
○ 同样,对于列联表中的 nij、ai 和 bj,
○ 方法 3: 调整互信息 (AMI)
○ 调整 NMI 以适应随机聚类的期望值。
○ 范围在 -1 和 1 之间。
○ 当类别较多或数据不平衡时,可有效消除随机聚类偏差。
○ 方法 4: Fowlkes-Mallows 指数 (FMI)
○ 精确率和召回率的几何平均值。
○ 范围在 0 和 1 之间。
○ 数据不平衡会导致性能下降。»> ○ 代码:
sklearn.metrics.fowlkes_mallows_score
○ 方法5:同质性
○ 测量具有相同标签的样本被分组为单个簇的程度。
○ 方法 6: 完整性
○ 评估同一簇内的样本属于同一标签的程度。
○ 方法 7: V 测量
○ 定义为:v = (1 + beta) × 均匀性 × 完整性 / (beta × 均匀性 + 完整性)
○ 范围在 0 和 1 之间。
⑶ 聚类的类型
① 类型1. 分层算法:根据某种距离测量连续分裂或合并组。
○ 确定性方法。
○ 1-1. 凝聚式:自下而上的方法。一种构建更大集群的方法。
○ 1-2. 分歧:自上而下的方法。一种分成更小的集群的方法。最常见的实现。
② 类型 2. 分区算法:寻找优化某些全局度量的特定划分
○ 2-1. 硬
○ 2-2. 软
⑷ 聚类对齐算法
① 聚类对齐的挑战:标签切换、多模态、不同的K值
② 示例 1. Gale–Shapley(稳定匹配)
○ 问题:两组(例如,男性/女性、学生/学校)各自比另一方有偏好排名。
○ 目标:找到一个稳定的匹配——没有阻塞对(即,没有两个参与者都比当前的匹配更喜欢对方)。
○ 主要特点:重点是稳定性,而不是成本最小化。结果对于提议方来说是最优的(提议者最优稳定匹配)。
③ 示例2. 匈牙利赋值算法
○ 问题:分配/二分匹配设置,其中每个可能的对都有一个成本(权重)。
○ 目标:找到最小化总成本(或同等地最大化总利润/效益)的最佳匹配。
○ 主要特点:注重优化,不注重稳定性;它不使用稳定匹配的概念。
○ 原理:如下图所示,它迭代地最小化有助于一对一匹配的组件成本,反之,最大化阻碍这种匹配的组件成本,从而找到最佳的一对一对应关系。
图1. 匈牙利分配算法
2.类型 1. 无监督层次聚类
⑴ 概述
① 常用于从内部矩阵绘制热图(示例:RStudio 的热图函数)
② 一类基于图的方法
③ 与非层次聚类不同,层次聚类不预先确定聚类的数量
⑵ 类型1. 分裂分析
① 从整个群体出发,分离出相似度递减的对象的技术
② 阶段1: 最初将N个元素分配给N个簇
③ 第2阶段: 将最接近的簇合并为一个
④ 阶段3:重复阶段2,直到满足簇数等约束
○ 在这种情况下,使用树状图
⑶ 类型 2. 凝聚层次聚类
①定义:将每个实体视为一个子组,逐步合并相似子组形成新子组的方法> ② 示例1. UPGMA(算术平均的未加权配对组法)
⑷ 链接度量:定义簇之间的距离
① 类型1. 单联动:一个簇的元素与另一个簇的元素之间的最短距离
② 类型2. 完全联动:一个簇中的元素与另一个簇中的元素之间的最远距离
③ 类型3. Average-linkage:两个簇中心之间的距离
○ 也可以表示一个簇与另一个簇的元素之间的平均距离
④ 类型4. 质心联动:测量两个簇中心之间的距离
⑤ 类型5. Ward-linkage:一种基于簇内平方和测量簇间距离的方法
图 2. 根据链接度量的聚类性能
⑸ 特点
① 与 K-means 聚类一样最常用的聚类算法之一
② 优点1.确定性:在任何环境下都能得出相同的结论
③ 优点2. 可以尝试各种联动标准
④ 缺点 1. 算法缓慢。一般需要Ο(n3)时间复杂度
○ 原因:执行第 2 阶段需要 Ο(n2),并且必须重复 Ο(n) 次
○ 在某些情况下,根据链接标准,需要 Ο(n2) 时间复杂度
⑹ 参考文献
3.类型 2. K 均值聚类
⑴ 概述
① 常用于针对图像的聚类算法
⑵ 算法
图 3. K 均值聚类的工作原理
① 阶段1: 随机选择k个初始质心
② 阶段 2: 根据每个元素最接近的质心分配簇
③ 第3阶段:计算每个簇的中心以定义新的质心
④ 阶段 4: 当质心不再变化时聚类结束
⑶ 特点
① 应用最广泛的聚类算法
② K-means聚类是聚类的贪心算法之一
③ 确定 K
○ 背景知识
○ 示例:区分生物多组学数据中的癌性数据和非癌性数据
○ 弯头法
○ 在聚类分析中通过绘制簇内总平方和与簇数的关系图并选择肘点作为适当的簇数来确定簇数的方法
○ 当聚类数为 x 轴、SSE 值为 y 轴时,选择坡度平缓的肘部对应的聚类
○ 轮廓法
○ 利用轮廓系数定量计算聚类质量的方法
○ 显示簇彼此分离的程度
○ 轮廓系数接近 1 表示优化良好、分离良好的簇
○ 轮廓系数接近 0 表示优化不佳、间隔紧密的簇
○ 树状图
○ 在层次聚类分析中使用树状图可视化来确定聚类数量
④ 优势
○ 优点 1. 速度快。 Ο(Kn) 执行阶段 2 所需的时间(K 是簇的数量,n 是数据点的数量)
○ 优点 2. 由于目标函数随着每次迭代而减小,因此在有限次数的迭代后在数学上会收敛
○ 优点3. 算法比较简单> ○ 优点4. 数据挖掘工具
⑤ 缺点
○ 缺点1. 应该给出K:选择错误的K会导致错误的结果
○ 缺点 2. 取决于初始质心:结果可能会根据初始质心位置而变化,因此它不是确定性的
○ 缺点3. 复杂的数据无法聚类,因为它依赖于特定点的欧氏距离。
○ 构成数据的每个特征都需要是双模态或多模态的才能正常工作。 ([参考](https://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_comparison.html))
○ 示例1: 当数据由两个同心圆组成时,两个质心的位置相同,因此无法使用K-means聚类。
○ 示例 2: 当簇不是球形时。
图 4. 当簇不是球形时
○ 示例 3: 当簇具有不同密度时。
图 5. 当簇具有不同密度时
⑥ 克服
○ ISODATA:估计 K 值
○ Kohonen 自组织图:与进化学习类似,逐渐增大 K 值以减少变异性
○ K-中心点聚类
○ Lloyd’s K-means 聚类算法
○ Bisecting K-Means:由[scikit包]提供(https://scikit-learn.org/stable/modules/clustering.html)
○ 模糊 c 均值聚类:点属于多个聚类。
○ Mean-shift:由scikit包提供。点被移动到附近最密集的区域。
⑷Python代码
受保护_0
⑸ 无监督层次聚类与 K 均值聚类
| 无监督层次聚类 | K 均值聚类 | |
|---|---|---|
| 时间复杂度 | O(n3) | O(kn) × 迭代 |
| 随机性 | 确定性 | 随机 |
桌子。 1. 无监督层次聚类与K-means聚类的比较
⑹ K-NN 与 K-means 聚类
| 项目 | K-NN | K 均值聚类 |
|---|---|---|
| 类型 | 监督学习 | 无监督学习 |
| k 的含义 | 最近邻居的数量 | 集群数量 |
| 优化技术 | 交叉验证,混淆矩阵 | 肘部法、轮廓法 |
| 应用 | 分类 | 聚类 |
表 2. K-NN 与 K-means 聚类
4。类型 3. 基于密度的聚类(DBSCAN,带有噪声的应用程序的基于密度的空间聚类)
⑴概述:K-means聚类等非层次聚类分析之一
① 根据密度计算对紧密分布的实体进行分组的算法
② 无需预先指定簇数
③ 簇根据簇密度连接,允许几何形状的聚类
⑵ 组成部分
①核心点
○ 在一定半径(epsilon)内其他数据点数量最少(min_samples)的数据点
○ 半径内所需的最小数据点数设置为超参数
② 邻点
○ 特定数据点周围一定半径范围内存在的其他数据
③ 边界点
○ 不是核心点,但存在于核心点的半径范围内
○ 包含在以核心点为中心的集群中,通常形成集群的外围
④ 噪声点» ○ 既不是核心点,又不满足边界点条件
○ 也被视为异常值
⑶ 程序
① 阶段1. 识别一定半径(epsilon)内最少数量(min_samples)点的核心点。
② 阶段 2. 仅使用核心点探索邻接图中的连通组件。
③ 阶段3. 将非核心点分配为噪声。
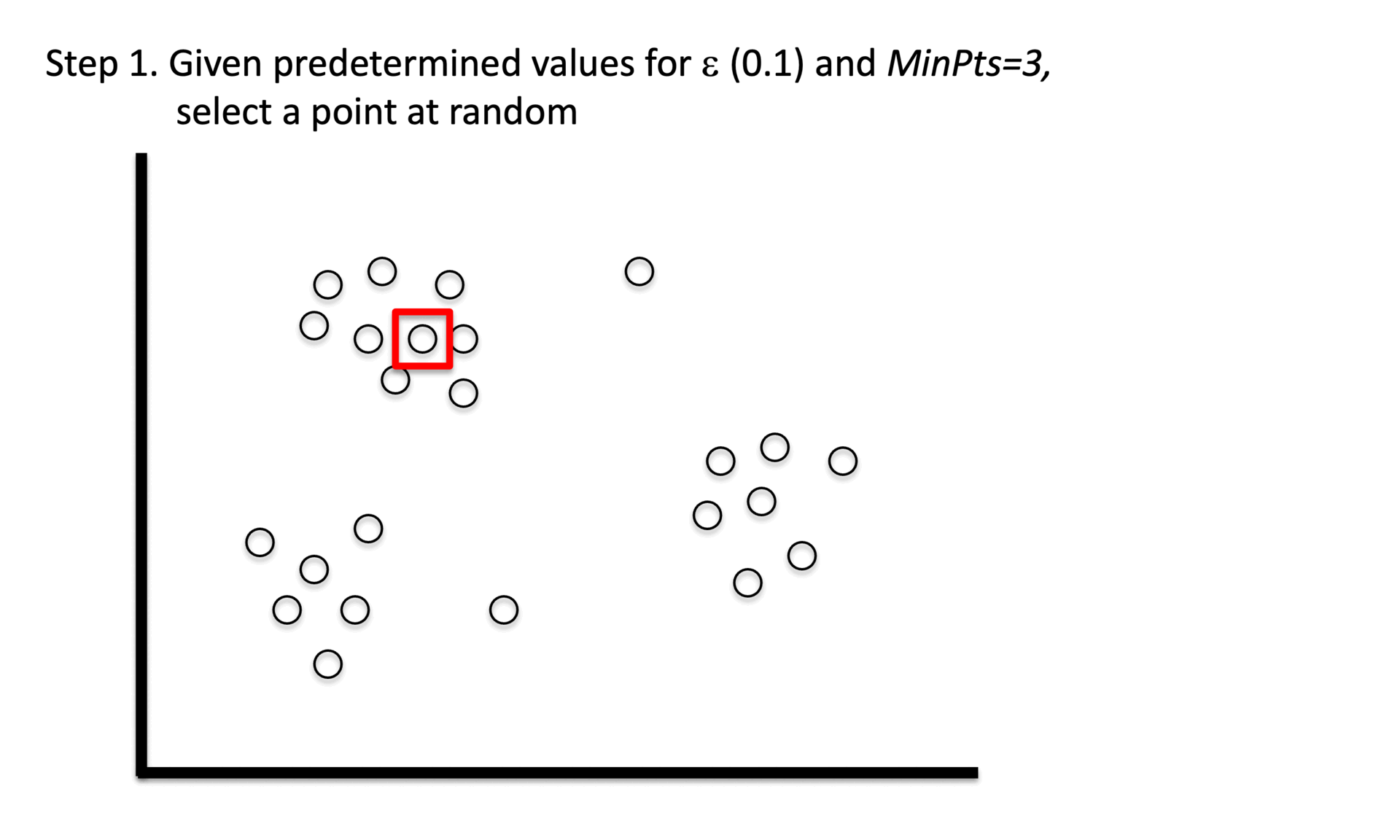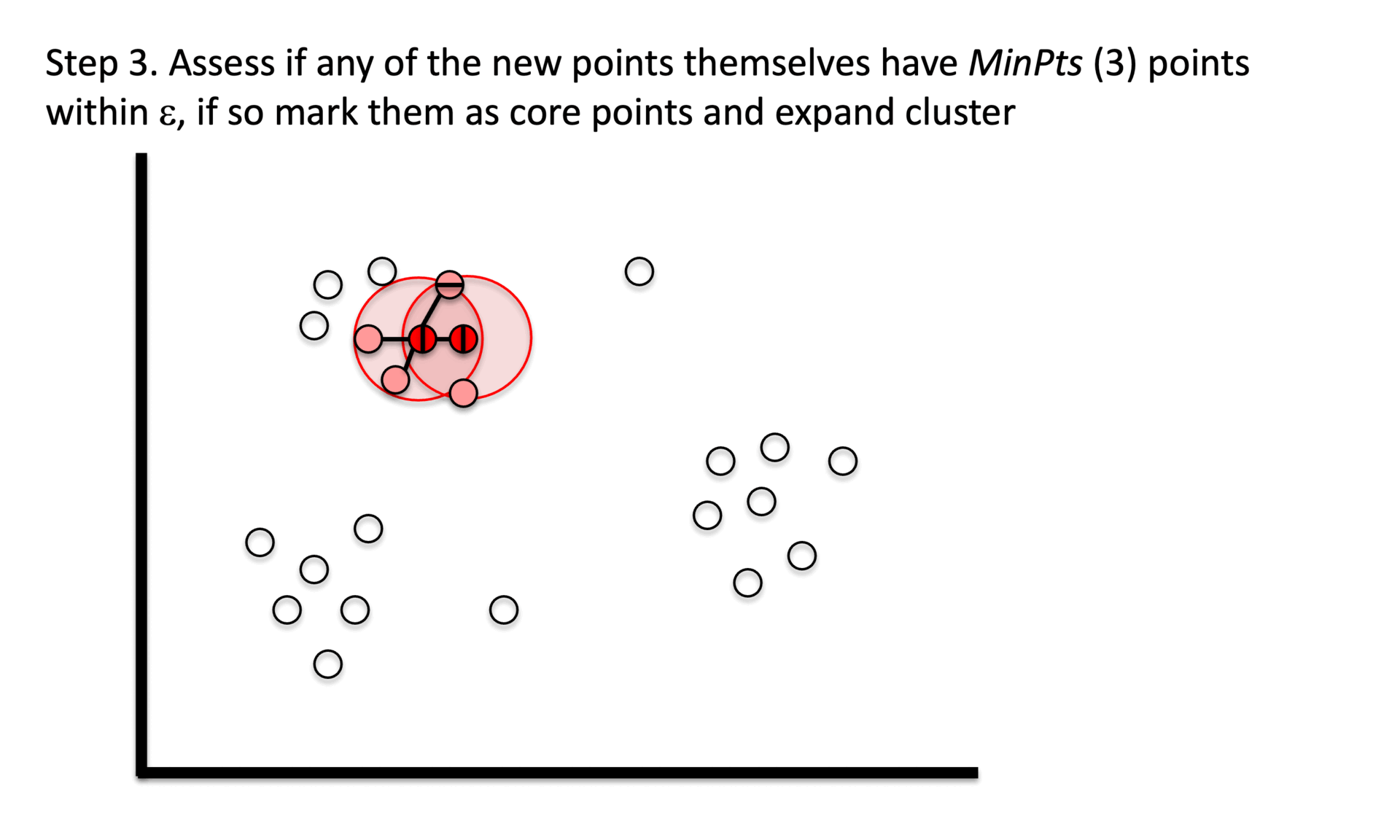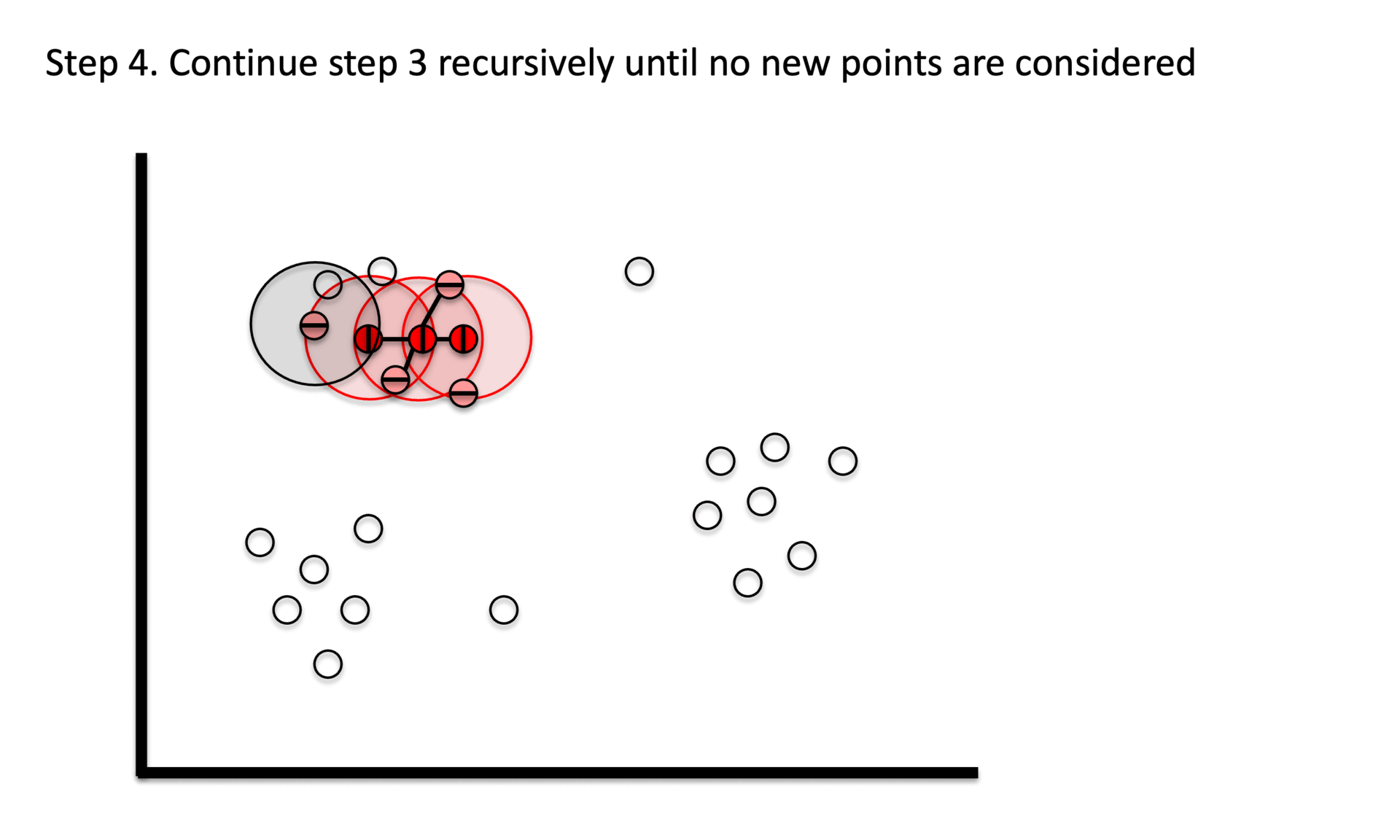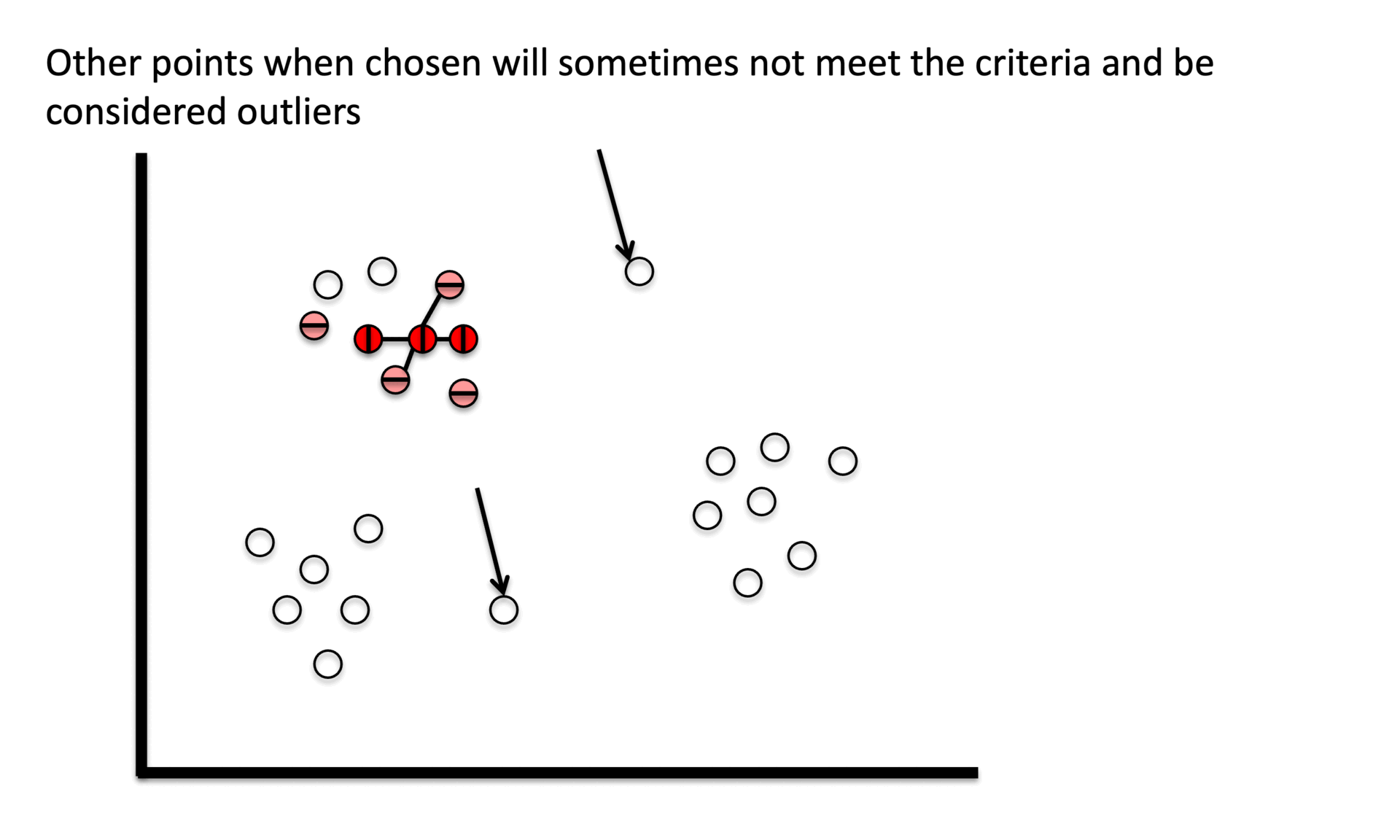
图 6. 吉布斯采样初始化
⑷ 特点
① 优点1. 不需要预先定义聚类的数量,与K-means聚类不同
② 优点2. 由于基于簇密度的聚类,可以识别具有几何形状的簇
③ 缺点1. 超参数确定困难,对参数选择敏感
④ 缺点 2. 当簇具有不同密度或更高维度时计算面临挑战
⑸ Python示例
图 7. DBSCAN Python 示例
受保护_1
⑹ 应用
① 光学
受保护_2
② HDBSCAN
受保护_3
③ DBSCAN++
5。类型 4. 混合分布聚类
⑴ 混合分布聚类:非层次聚类分析的一种,如 K-means 聚类
① 假设数据来自表示为 M 个参数模型的加权和的总体模型,根据数据估计参数和权重
② M个模型中的每一个代表一个簇,每个数据点根据它最有可能来自哪个模型被分类到一个簇中
③ 混合模型的定义:表示为M个分布(分量)的加权和的混合模型
p(x | θ) = Σ p(x | Ci, θi) p(Ci)
○ p(x Ci, θi): 混合模型中的个体概率密度函数
○ θi:第i个分布的参数向量
○ Ci: 第 i 个簇(类)
○ p(Ci): 混合模型中第 i 个簇的重要性或权重 (αi)
④ 混合模型的参数估计比单一模型复杂,经常使用EM算法而不是微分
⑤ 如果簇的大小太小,估计的准确性可能会降低或变得具有挑战性
⑥ 对异常值敏感,需要进行异常值去除等预处理
⑵ 高斯混合模型(GMM)
图 8. 高斯混合模型
① 概述
○ 假设整体数据概率分布是 k 个高斯分布的线性组合。
○ 聚类是根据属于每个分布的概率形成的。
○ 构成数据的每个特征都需要是双模态或多模态的才能正常工作。 ([参考](https://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_comparison.html))
② 公式
○ 在 GMM 中,估计给定数据 X = {x1, x2, …, xN} 的适当 k 高斯分布的权重、均值和协方差
○ 化简:当x为一维数据时
○ 矩阵表示:当x为多维数据时,对于第k个簇的均值μk和协方差矩阵Σk
③ EM算法(MLE估计)
○ EM算法可用于估计每个数据点所属的最优高斯分布
○ 目标函数:表示为对数似然
○ 第 1 步: 为 γi,k 分配随机值
○ 第2步: E步:估计γi,k
○ 步骤 3: M 步骤:根据 γi,k 计算 ak、μk、Σk
○ 步骤4: 如果 γi,k 收敛,则停止;否则,转到步骤2:由于高斯函数的特性,保证了收敛性。
④ K均值聚类与高斯混合模型的比较
图9. K均值聚类与高斯混合模型的比较
6。类型 5. 基于图的聚类(SOM,自组织映射)
⑴概述:非层次聚类分析之一,如K-means聚类
① SOM,由 Kohonen 开发,也称为 Kohonen 地图
② SOM是模仿大脑皮层和视觉皮层学习过程的人工神经网络
③ 通过自主学习方法进行聚类
④ 一种无监督神经网络,将高维数据映射成易于理解的低维神经元排列
⑤ 映射保留了输入变量的位置关系
⑥ 在实际空间中,如果输入变量很接近,则它们在图上的映射也很接近
⑦ 由于仅使用一次前向传递,速度非常快
⑵ 类型1. SOM
① 组件1. 输入层
○ 接收输入向量,包含等于输入变量数量的神经元
○ 输入层数据通过学习在竞争层对齐,简称为map
○ 输入层中的每个神经元与竞争层中的每个神经元完全连接
② 组件 2. 竞争层
○ 排列在 2D 网格中的层,其中输入向量根据其特征聚集成单个点
○ SOM 采用竞争学习,每个神经元计算其与输入向量的接近程度,反复调整连接强度
○ 通过学习过程,连接强度使得与输入模式最相似的神经元获胜
○ 由于赢家通吃的结构,只有获胜的神经元出现在竞争层中,相似的输入模式排列在同一个竞争神经元中
③ 学习算法
○ 步骤 1. 初始化:初始化 SOM 图中节点的连接强度
○ 步骤2. 输入向量:呈现输入向量
○ 步骤3. 相似度计算:使用欧氏距离计算输入向量和原型向量之间的相似度
○ 步骤4. 原型向量搜索:找到最接近输入向量的原型向量(BMU)
○ 步骤5. 强度调整:重新调整BMU与其邻居的连接强度
○ 步骤 6. 重复:返回步骤 2 并重复⑶ 类型2. 谱聚类
① 问题定义
○ 条件 yTDy=1 是必要的原因:如果没有这个条件,则存在一个平凡解 y=0,并且对于任何非零 y,存在一个 0 ≤ 𝑐 < 1 0≤c<1 的标量 c,使得 cy 使目标函数任意小。
○ 需要条件 yTD1=0 的原因:该条件对于 y≠1(正交性)是充分必要的。如果没有它,目标函数的最小值始终为 0,并且始终在 y=1 处实现(通过拉格朗日乘子 的方法)。
② 步骤1:计算给定的n个数据点之间的距离,创建一个n×n的邻接矩阵A。
○ 经常使用高斯核。
③ 步骤2:根据邻接矩阵,计算【拉普拉斯矩阵】(https://jb243.github.io/pages/616) L:也可以使用Ln或Lr。
○ L = D - A,其中 Dii = Σj Aij
○ Ln = D-1/2LD-1/2 = I - D-1/2AD-1/2
○ Lt = D-1A
○ Lr = D-1L = I - Lt = D-1/2LnD1/2
④ 步骤3:计算拉普拉斯矩阵的k个最小特征值对应的特征向量矩阵W = [ω2,…,ωk] ε ℝn×k。
○ 特征值越接近0,图的连通性越强。
○ 排除 ω1 = 1,它对应于 λ1 = 0,因为它是微不足道的。
⑤ 步骤4:将n个数据点自然地嵌入到k维中:Y = WT = [y1, ⋯, yn],每个列向量代表嵌入的数据点。
⑥ 步骤5:对Y的列向量进行聚类,例如K-means聚类。
⑷ 类型 3. Louvain 聚类:使用 Louvain 模块化优化。一种基于图的方法
图10. Louvain聚类原理
⑸ 类型 4. Kernighan-Lin 算法:使用 Pearson 相关最大化。
⑹ 类型 5. 随机块建模:使用统计推断。
⑺ 类型 6. 莱顿聚类
① 基于图的聚类方法
② scanpy pipeline中使用的Leiden算法
受保护_4
7.其他聚类算法
⑴ 基于SNN(共享最近邻)模块化优化的聚类算法
① 步骤1. 搜索K近邻
② 步骤2. 构建SNN图
③ 步骤3. 优化模块化功能以定义集群
④ 参考论文:Waltman 和 van Eck (2013)欧洲物理杂志 B
⑵ 【主题建模】(https://jb243.github.io/pages/956#5-type-4-latent-topic-model):LDA、NMF、CountClust (Dey et al., 2017)、FastTopics (Carbonetto et al., 2023)
⑶ 均值漂移聚类
⑷ NMF(非负矩阵分解)
① 将已知矩阵A分解为矩阵W和H的乘积的算法:A ~ W × H
○ A Matrix:样本特征矩阵,由样本可知» ○ H Matrix:可变特征矩阵
○ 这有助于提取元基因
○ 类似于K均值聚类、PCA算法
② 算法:搜索满足 R = UV、R ε ℝ5×4、U ε ℝ5×2、V ε ℝ2×4 的 U、V。
受保护_5
③ NMF(非负矩阵分解)
受保护_6
④ 矩阵补全(例如 Netflix 算法):将矩阵分解应用于矩阵 R 的屏蔽版本的过程。
受保护_7
⑤ SVD(奇异值分解)
⑥ 应用1. 细胞类型分类
○ 用于通过从组织获得的 scRNA-seq 确定细胞类型比例
○ 对于减少细胞类型异质性的混杂效应很重要
○ 1-1. 约束线性回归
○ 1-2. 基于参考的方法
○ 1-2-1. CIBERSORT(通过估计 RNA 转录本的相对子集进行细胞类型识别):允许检查细胞类型比例、每个样本的 p 值
⑦ 应用2. 联合NMF:扩展到多组学
⑧ 应用3. 提取元基因
⑨ 应用 4. Starfysh:下面描述了一种从空间转录组数据推断原型并识别代表每个原型的锚点的算法。
○ 步骤1. 自动编码器构建
○ X ∈ ℝS×G:输入数据(点×基因)
○ D:原型数量
○ B ∈ ℝD×S:编码器。这代表了原型的推论。每个原型在所有点上的分布总和应为 1。
○ H = BX:潜变量
○ W ∈ ℝS×D:解码器。这将重建输入数据。每个点的所有原型权重之和应为 1。
○ Y = WBX:重构输入
○ 步骤 2. 解决优化问题以计算 W 和 B
○ 步骤 3. 从 W 矩阵中选择锚点作为每个原型具有最高权重的点。
○ 步骤 4. 粒度调整:如果原型彼此接近,则使用分层结构对它们进行合并或调整。
○ 步骤 5. 对于每个锚点,识别最近的点以形成原型群落,并探索标记基因。
○ 步骤 6. 当提供特征基因集时,原型标记基因将添加到现有基因集中,并重新计算锚点。
○ 在此步骤中,使用稳定的婚姻匹配算法将每个原型与最相似的签名进行配对。
⑸ 边缘检测算法
① 类型1. Canny 边缘检测
○ 步骤1. 高斯模糊
○ 步骤2. 查找边缘梯度强度和方向
○ 步骤3. 沿边缘追踪:如果梯度大小大于某个值,则根据边缘方向选择下一个像素
○ 步骤 4. 抑制非极大边缘:删除与强边缘平行的弱边缘
② 类型2. 面向区域的分割
○ 步骤 1. 从一组种子点开始
○ 步骤 2. 从种子点开始,通过将具有相似属性的相邻像素附加到每个种子点来增长区域。
○ 缺点:种子点选择、参数选择合适、缺乏停止规则
图11. 面向区域的分割(请注意,T = 3 表示值差异的截止)
③ 类型3. 区域分割与合并
○ 步骤 1. 将图像分割为四个不相交的象限。
○ 步骤 2. 合并任何相似的相邻区域。
○ 步骤 3. 当无法进一步合并或拆分时停止。
○ 缺点:耗时较长,但可以通过并行计算来缓解。
图12. 区域分割和合并
⑹【分水岭算法】(https://opencv-python.readthedocs.io/en/latest/doc/27.imageWaterShed/imageWaterShed.html)
① **一种基于阈值(例如某些亮度级别)识别图像中 ROI 的算法
⑺ 阈值法
①定义:基于阈值创建二值图像的技术
② 示例:【大津阈值法】(https://github.com/mohabmes/Otsu-Thresholding)
⑻ MST(最小生成树)
⑼ 曲线演化
⑽ 稀疏邻接图:一种基于图的方法
⑾ SC3
⑿ SIMLR
⒀ 信息通信技术
⒁ Faiss
① Meta于2023年开发的基于相似度的搜索和密集向量聚类算法。
② 快速搜索算法:能够获得最近邻和第k最近邻。
③ 允许一次搜索多个向量(批处理)。
④ 精度和速度之间需要权衡。
⑤ 不是最小化欧氏距离,而是通过最大化最大内积来计算。
⑥ 返回给定半径内包含的所有元素。
⒂ 集群
⒃ PAM 聚类
⒄ 亲和力传播:由[scikit包]提供(https://scikit-learn.org/stable/modules/clustering.html)
⒅ BIRCH:由[scikit包]提供(https://scikit-learn.org/stable/modules/clustering.html)
输入时间:2021.11.16 13:17
编辑时间:2025.04.02 00:20