第 15 章。方差分析 (ANOVA)
高级类别:【统计】【统计概述】(https://jb243.github.io/pages/1641)
1. 方差分析
2. 单向方差分析
3. 双向方差分析
1.方差分析 (ANOVA)
⑴定义n:比较n组的统计分析(假设n>2)
⑵ Ⅰ型错误膨胀:在n个组中进行t检验时出现问题(假设n>2)
① 1 组没有 Ⅰ 型错误的概率(显着性水平 5%): 0.95
② n 个组全部不存在 Ⅰ 型错误的概率(显着性水平 5%): 0.95n
③ n 个组至少出现一次 Ⅰ 型错误的概率(显着性水平 5%) : 1 - 0.95n ≫ 0.05
④由于Ⅰ型误差膨胀,引入ANOVA
⑶ 假设: 这些是单向方差分析和双向方差分析所必需的
①常态
○ 定义: 所有数据均从遵循正态分布的总体中提取
○ 正态性检验类型:Q-Q 图、Shapiro-Wilk 检验、Kolmogorov-Smirnov 检验、D’Agostino-Pearson 检验
○ 如果总体难以视为正态分布,请使用幂变换或对数变换使它们类似于正态分布
○ Welch 方差分析 F 检验不假设同方差性。
○ 这里,考虑了一些人口,因为人口的手段可能会有所不同

图 1. 通过对数变换生成模拟正态分布的示例
②独立性:也称为i.i.d。
○ 定义 : 每个数据都是从总体中独立提取的
○ 与实验设计相关
○ 这里,考虑了一些人口,因为人口的手段可能会有所不同
③同方差性
○ 定义 : 所有数据均来自具有相同方差的总体,即使总体的均值不同
○ 若最大方差与最小方差之比不超过4:1,可采用方差分析
○ 如果很难使用 ANOVA,请使用平方根变换来最小化方差差异
○ 回归分析中的等方差意味着 Yi 的方差对于每个 Xi: 方差分析和回归分析之间同方差的含义略有不同
○ 如果不满足同方差性,则应应用 Welch 方差分析
⑷ 鲁棒性
①定义:在满足大量样本、类别内重复次数相同等情况下,即使存在异方差性和非正态性,统计结论也不会改变的特征
② ANOVA 的稳健性 : ANOVA 比其他方法更适用,即使其同方差性和正态性不严格满足
③回归分析的稳健性:添加或改变回归变量不会显着改变特定系数值的特征
⑸(比较)回归分析与交叉分析
①方差分析:自变量是分类(分类)变量。因变量是可测量变量
②交叉分析:自变量是分类(分类)变量。因变量是分类(分类)变量
③回归分析:自变量是可测量变量。因变量是可测量变量
## 2.单因素方差分析
⑴定义:方差分析中只有1个自变量和1个因变量的情况
① 自变量称为治疗效果或因子
②适当因变量的例子:{身高},{体重}(O)
③不适当因变量的例子:{身高、体重}(X)
⑵ 单因素方差分析模型
① 模型1. 固定效应模型
○ 定义: 比较某些物体的效果。换句话说,因素的水平是固定的
○ 方法: 不需要从群体中进行提取试验。事后分析很重要
○ 示例: 对照、治疗 A、治疗 B
② 模型2. 随机效应建模
○ 定义:着眼于人口总体趋势。换句话说,因素的水平是随机的
○ 方法:从总体中随机抽取样本并进行方差分析。不需要事后分析
○ 示例 : 当工厂老板想要确保所有工厂产品的重量相同时
③ 单向方差分析中,固定效应建模和随机效应建模遵循相同的计算流程
⑶ 问题情况
| 因素 | 第 1 组 | 第 2 组 | 第 3 组 |
|---|---|---|---|
| 样品 | 11 | 11 8 | 5 |
| 10 | 10 7 | 4 | |
| 8 | 5 | 2 | |
| 7 | 4 | 1 | |
| 平均 | 9 | 6 | 3 |
表 1. 单向方差分析示例
① X̄1 = 9, X̄2 = 6, X̄3 = 3, X̄ = 6
② 第1组、第2组、第3组的样本量允许不同
⑷ 设定假设
① H0 : μ组 1 = μ组 2 = ··· = μ组 m = μ(假设上述情况中 m = 3)
② H1 :至少有一对总体均值不相等
⑸ F统计量的推导
① 想法:如果组内方差明显小于组间方差,则可以说样本组之间存在差异
②定义

③ 平方和(SS)

④ 方差比的计算
○ 方差比: 也称F比
○ 组间方差: 与误差和治疗效果相关
○ 组内方差: 与误差相关

⑤ 结果表
| 因素 | 平方和 | 自由度 | 平方均值 | F 比 | p值 | |
|---|---|---|---|---|---|---|
| 效果 | 72 | 72 2 | 36 | 36 10.8 | 10.8 0.0040583 | 0.0040583 |
| 误差(残差) | 30 | 9 | 3.33 | 3.33 | ||
| 总和 | 102 | 102 11 | 11 |
○ 误差平方和 = 组间方差 + 组内方差 = 72 + 30 = 102
○ 总自由度 = 组间方差自由度 + 组内方差自由度 = (k - 1) + (n - k) = n - 1
○ 组变量不是数字,因此计算决定系数没有意义
○ 报告示例: “单因素方差分析显示三种处理之间存在显着差异(第 1 组、第 2 组和第 3 组): F2.9 = 10.8,p < 0.01”» ○ 提示。 计算 72 和 30 时,使用 12 项(∵ 对称性)
⑹ F统计量的证明
①【样本分组及样本分布】(https://classroom.tistory.com/42)
②组间方差分布

③组内方差分布
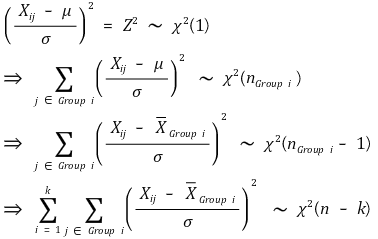
④方差比分布

⑺ 特点
① 如果每组的样本数量相似,则功效较高
② 如果特定组的样本数量较少,可靠性值得怀疑
③ 拒绝备择假设并不总是得出配对 t 检验中一对均值不同的结论
④ 与配对t检验不同,事后分析(海报分析)表明哪对组是不同的
⑻ Levene检验:异方差检验


图 2. Levene 测试示例
① 第一第一。检查每个偏差的绝对值,计算为与每个相关样本组平均值的差异
○ 控制: (8, 7, 7, 8)
○ 肿瘤抑制器: (2, 1, 1, 2)
○ 抑制素 4: (2, 1, 1, 2)
② 第二第二。对三个新组执行单向方差分析
③ 第三第。与其他两组相比,对照组明显显示出较大偏差:拒绝同方差
④ 其他异方差性检验:Bartlett 检验
⑼事后分析:基本上是通过多重比较得出的
① LSD、Bonferroni、Sidak、Tukey、Duncan、Dunnett、Scheffe、Student-Newman-Keuls、BH 程序等
○ Scheffe、Tukey、Duncan 和 Student-Newman-Keuls 最受欢迎
○ 三者中,谢夫最保守,邓肯最宽松
○ 自然科学中: 一般首先进行Tukey检验,如果Tukey检验不显着则使用Duncan
○ 在社会科学中: 一般来说,Scheffe 被频繁使用
② 示例:Tukey HSD(确实显着差异,Tukey-Kramer 方法)
○ 与Bland-Altman测试不同。
○ 统计

○ 测试


图3.方差分析后的多重比较测试
○ 情况1. 样本均值中A>B>C>D>E
○ 情况 2. 作为单向方差分析的结果,所有均值不相等
○ 第一第一。按照 A-E、A-D、A-C、A-B 的顺序用 Tukey 统计量进行检验: A-C 不显着,因此省略 A-B 检验 » ○ 第二第二。按照 B-E、B-D、B-C 的顺序用 Tukey 统计量进行检验 : A-C 不显着,因此省略 B-C 检验
○ 第三第。按 C-E 和 C-D 的顺序使用 Tukey 统计量进行检验
○ 第 4。使用 Tukey 统计量检验 D-E
○ 如果不按大小排序,总共10次测试会出现10次Ⅰ型错误,即Ⅰ型错误膨胀
○ 在上述情况下,情况稍好一些,因为仅出现了 8 次 Ⅰ 类错误
③事后分析时的注意事项
○ 示例
| 控制 | 神经抑制素 | 米托斯特 |
|---|---|---|
| 7 | 4 | 1 |
| 8 | 5 | 2 |
| 10 | 10 7 | 4 |
| 11 | 11 8 | 5 |
表 3. 事后分析示例
○ 结果

图 4. 事后分析中的注意事项
○ Control = Neurohib、Neurohib = Mitostop,但 Control ≠ Mitostop 的原因是Ⅰ型错误
○ 示例 : 如果 A = B 的概率为 10%,B = C 为 10%,则 A = B = C 的概率为 1%,这是显着不同的
3。双向方差分析
⑴概述
① 定义 : 尝试对两个自变量、一个因变量进行方差分析
② 不仅每个因素的主效应值得关注,而且它们之间的相互作用也值得关注
③假设
○ 正态性 : 总体服从正态分布
○ 独立性:样本是从总体中随机抽取的
○ 同方差 : 总体具有相同的方差
○ 正交性 : 两个因素彼此不相关
○ 对正交性的满意与没有交互无关:理解概念上的差异是必要的。
⑵ 情况分类

图5.双因素实验结果分类
⒜ 无温度影响;无湿度影响
⒝无温度影响;存在湿度影响
⒞ 存在温度影响;无湿度影响
⒟ 存在温度影响;存在湿度影响
⒠ 存在温度影响;存在湿度影响;存在的相互作用
⑶ 双向方差分析模型
① 在双向方差分析中应以不同方式计算随机效应的原因

图 6. 在双向方差分析中应以不同方式计算随机效应的原因
○情况: B2和B4是从因子B中随机提取的水平
○ 期望 : A 的主效应应该是不明确的
○现实:由于随机抽样效应,A的主效应似乎是存在的
② 模型1.固定效应模型:两个因子的水平是固定的
| 因素 | 平方和 | 自由度 | 平方均值 | F 比 | ||
|---|---|---|---|---|---|---|
| 一个 | SSA | dfA = I-1 | dfA = I-1 | MSA = SSA ÷ dfA | FA = MSA ÷ MSE | |
| 乙 | SSB | dfB = J-1 | MSB = SSB ÷ dfB | FB = MSB ÷ MSE | ||
| 甲 × 乙 | SSA×B | dfA×B = (I-1)(J-1) | MSA×B = SSA×B ÷ dfA×B | FA×B = MSA×B ÷ MSE | ||
| 误差(残差) | SSE | dfE = n-IJ | dfE = n-IJ | MSE = SSE ÷ dfE | ||
| 总和 | 海温 | n-1 | n-1 |
表4.固定效应建模结果表
③ 模型2.随机效应建模:两个因子的水平是随机的
| 来源 | 平方和 | 自由度 | 均方 | F 比 | |
|---|---|---|---|---|---|
| 一个 | SS_A | df_A = I - 1 | MS_A = SS_A ÷ df_A | F_A = MS_A ÷ MS_A×B | |
| 乙 | SS_B | df_B = J - 1 | df_B = J - 1 | MS_B = SS_B ÷ df_B | F_B = MS_B ÷ MS_A×B |
| 甲 × 乙 | SS_A×B | df_A×B = (I - 1)(J - 1) | df_A×B = (I - 1)(J - 1) | MS_A×B = SS_A×B ÷ df_A×B | F_A×B = MS_A×B ÷ MS_E |
| 误差(残差) | SS_E | df_E = n - IJ | df_E = n - IJ | MS_E = SS_E ÷ df_E | |
| 总计 | SS_T | n - 1 | n - 1 |
表5.随机效应建模结果表
④ 模型3.混合效应模型:一个因子具有固定水平,另一个因子具有随机水平
| 因素 | 平方和 | 自由度 | 平方均值 | F 비 | |
|---|---|---|---|---|---|
| 一个 | SSA | dfA = I-1 | dfA = I-1 | MSA = SSA ÷ dfA | FA = MSA ÷ MSA×B |
| 乙 | SSB | dfB = J-1 | MSB = SSB ÷ dfB | FB = MSB ÷ MSE | |
| 甲 × 乙 | SSA×B | dfA×B = (I-1)(J-1) | MSA×B = SSA×B ÷ dfA×B | FA×B = MSA×B ÷ MSE | |
| 误差(残差) | SSE | dfE = n-IJ | dfE = n-IJ | MSE = SSE ÷ dfE | |
| 总和 | 海温 | n-1 | n-1 |
表6.混合效应建模结果表
○ A为固定效应,B为随机效应
○ 提示. 通过与下面的嵌套方差分析进行比较来理解
⑷ 示例:固定效应建模
| 湿度(%) | 温度(℃) | |||
|---|---|---|---|---|
| 20 | 30 | 40 | 40 | |
| 33 | 33 1 | 5 | 9 | |
| 2 | 6 | 10 | 10 | |
| 3 | 7 | 11 | 11 | |
| 66 | 66 9 | 13 | 17 | 17 |
| 10 | 10 14 | 14 18 | 18 | |
| 11 | 11 15 | 15 19 | 19 | |
| 99 | 99 17 | 17 21 | 21 25 | 25 |
| 18 | 18 22 | 22 26 | 26 | |
| 19 | 19 23 | 23 27 | 27 |
表。 7. 双向方差分析示例

①定义

② 平方和

③方差比的计算

④ 结果表
| 因素 | 平方和 | 自由度 | 平方均值 | F 比 | p值 | |
|---|---|---|---|---|---|---|
| 温度 | 288 | 288 2 | 144 | 144 144 | 144 8.43e-12 | 8.43e-12 |
| 湿度 | 1152 | 1152 2 | 576 | 576 576 | 576 < 2e-16 | |
| 温度×湿度 | 0 | 4 | 0 | 0 | 1 | |
| 误差(残差) | 18 | 18 18 | 18 1 | |||
| 总和 | 1464 | 1464 26 | 26 |
表 8. 结果表
○ 零假设 1. μ20℃ = μ30℃ = μ40℃ = μ : 拒绝该零假设,因为 p 值 = 8.43e-12 < 0.05
○ 零假设 2. μ33% = μ66% = μ99% = μ : 拒绝该零假设,因为 p 值 < 2e-16 < 0.05
○ 零假设 3. 温度和湿度的相互作用 = 0: 不会拒绝该零假设,因为 p 值 = 1
○ 【决定系数】(https://jb243.github.io/pages/1632) = 1 - 18 ÷ 1464 = 0.987704918
○ 相关系数 = ± √ 0.987704918 = 0.993833445
○ 相关系数的符号根据斜率估计器的符号确定
⑤ 交互作用掩盖了主效应,所以不要相信存在显着交互作用时的F值
○ 例如,如果A物质促进基因表达,B物质抑制基因表达,
○ A物质和B物质同时处理时,基因表达无明显变化
○ 不过,A 和 B 都不是无效的。
⑸ 应用1. 无需复制的测试
①概述
○ 单向方差分析不可能
○ 当实验群体数量不足或费用昂贵时使用
② 示例
| 辐射水平 | 药品 | 平均 | |||
|---|---|---|---|---|---|
| 普罗希布 | 睾丸块 | 控制 | |||
| 低 | 81 | 81 76 | 76 79 | 79 78.67 | 78.67 |
| 中等 | 45 | 45 46 | 46 45 | 45 45.33 | |
| 高 | 28 | 28 27 | 27 27 | 27 27.33 | 27.33 |
| 平均 | 51.33 | 51.33 49.67 | 49.67 50.33 | 50.44 | 50.44 |
表 9. 不进行复制的测试示例
③ 结果表
| 因素 | 平方和 | 自由度 | 平方均值 | F 比 | p值 | |
|---|---|---|---|---|---|---|
| 药品 | 4070.222 | 2 | 2035.111 | 2035.111 832.546 | 5.74e-06 | |
| 辐射 | 4.222 | 4.222 2 | 2.111 | 2.111 0.864 | 0.864 0.488 | 0.488 |
| 误差(残差) | 9.778 | 9.778 4 | 2.444 | 2.444 | ||
| 总和 | 4084.222 | 8 |
表10.未重复检验的方差分析结果表
○ 没有重复的测试方差分析不应包含交互项
○ 如果包含交互项,则该项的残差自由度 = (RC - 1) - (R - 1 + C - 1 + (R - 1)(C - 1) = 0,因此无法计算F比
⑹ 应用2.随机区组实验设计:非重复方差分析的例子
①定义:将区域划分为若干块后,每个块再次细分以实验不同的Factor

图 7. 随机区组实验设计
○ 双向方差分析是可能的: 有两个因素;区域特定因素和治疗因素 » ○ 目的:通过分离区域特定因素来提高治疗统计结论的可靠性
② 流程
○ 第一第一。将整个区域划分为几个区域
○ 第二第二。为每个区域随机分配块号
○ 第三第。每个块被分为与处理级别数一样多的子块
○ 第 4。随机分配每个子块上处理级别的位置
○ 第五th。对每个块中的每个处理重复测量
○ 第六th。具有统计显着性的块因子表明明显存在区域特定因子
○ 地区特定因素: 地下水的存在、日光差异、地下矿脉的存在等
③结果

表11.随机区组实验设计的结果
⑺ 应用3. 方差的嵌套分析
① 模拟双向分析 :现实中属于单向方差分析
② 示例
○ 问题情况
| 虾粮+维生素A | 虾食品 | |||
|---|---|---|---|---|
| 池塘 1 | 池塘 2 | 池塘 3 | 池塘 4 | |
| 30 | 60 | 80 | 110 | 110 |
| 35 | 35 65 | 65 85 | 85 115 | 115 |
| 45 | 45 75 | 75 95 | 95 125 | 125 |
| 50 | 50 80 | 100 | 100 130 | 130 |
表12.嵌套方差分析的情况

图8.嵌套方差分析的情况
○ F统计量的计算
| 因素 | 平方和 | 自由度 | 平方均值 | F 比 | p值 | |
|---|---|---|---|---|---|---|
| 饮食 | 10000.0 | 1 | 10000.0 | 5.556 | 5.556 0.143 | 0.143 |
| 池塘(饮食) | 3600.0 | 3600.0 2 | 1800.0 | 21.600 | 21.600 0.000 | 0.000 |
| 误差(残差) | 1000.0 | 1000.0 12 | 12 83.3 | 83.3 | ||
| 总和 | 14600.0 | 14 | 14 |
表13.嵌套方差分析中F统计量的计算
○实际计算:计算10000、3600、1000时,右侧项数为16(∵对称性)

③ 类似于随机区组实验设计,但存在明显差异
○ 区别1. 池塘1、池塘2、池塘3、池塘4不能划分为任何区块
○ 差异2. 不满足正交性,这基本上是双向方差分析的假设: Diet 和 Pond(Diet) 不正交
○ 差异3.自由度计算的差异:Pond(Diet)的自由度总共为2,其中Pond 1 ↔ Pond 2和Pond 3 ↔ Pond 4
○ 在上例中,如果您正在设计随机区组实验设计,则区组的自由度为 1
○ 随机区组实验设计增加了误差自由度,从而提高了F比(提高了检验的功效)

○ 我们旨在设计随机区组实验设计而不是嵌套方差分析的原因
○ 差异 4. 像池塘 × 饮食一样计算,而不将池塘视为独立因素
输入时间:2019.11.16 17:36