第 13 章.统计估计
高级类别:【统计】【统计概述】(https://jb243.github.io/pages/1641)
1. 概述
2. 点估计
3. 区间估计
1.概述
⑴统计估计:通过样本估计一个总体的特征
⑵状态空间:ℝn。所有观察到的样本的集合
2.点估计(参数方法,位置类型)
⑴定义:从样本中估计参数(x1,…,xn)
①参数:显示总体特征的数值。 μ、σ、θ、λ 等
② μ:总体平均值
③ σ:总体标准差
④ θ:θ:伯努利分布或二项式分布成功的概率
⑤ λ:泊松分布或指数分布的λ
⑵ 抽样分布(经验分布)
⑶点估计器:对于参数θ,
① 定义1.点估计器不是单个数字而是一个函数
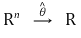
② 定义2.点估计器是X1,…,Xn的函数
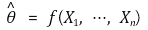
③ 定义 3. 点估计器的概率是 θ 的函数
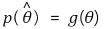 </中心>
</中心>⑷ 优秀点估计器的标准
① 预期误差或均方误差(MSE):也称为模型风险
○ 偏差-方差分解
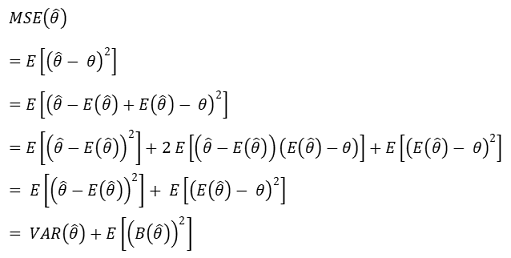 </中心>
</中心>○ 由于直观上偏差和机会误差的协方差为0,所以可以去掉中间项
○ 减少偏差的策略会增加模型方差
○ 减少模型方差的策略会增加偏差
② 标准1.偏差:也称为系统误差、非随机误差、模型偏差
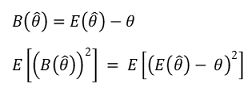
○ 需要小偏差
○ 原因: 拟合不足,缺乏领域知识
○ 解决方案: 使用更复杂的模型,使用适合领域的模型
○ 无偏估计量: B = 0 ⇔ 样本平均值 = 总体平均值。如果存在无偏性,那么它就是一个很好的估计器
○ 示例 1. 样本均值: 总体均值的无偏估计量
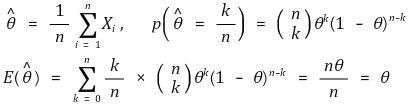
○ 示例 2. 样本方差:总体方差的无偏估计量
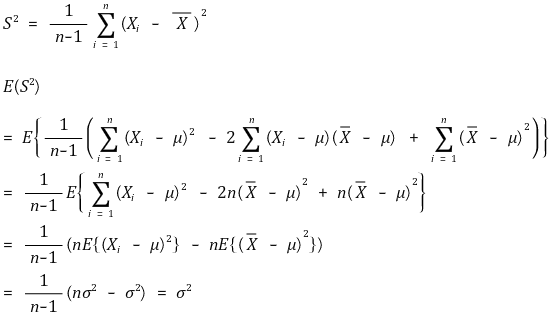
○ 示例 3. 样本协方差
</中心>
○ 示例 4. 当 Xi ~ u[0, θ] 时,是否为无偏估计量
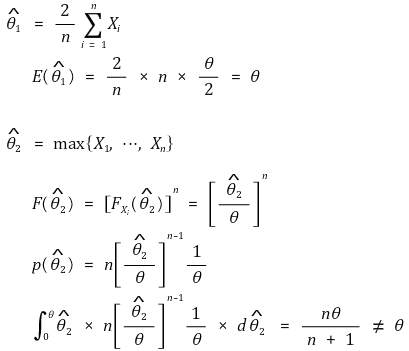
③ 标准2.效率:与随机机会误差相关

○ 在无偏估计的前提下要求方差小
○ 2-1. 噪声方差: 也称为第一机会误差和观察方差。标记为 σ2
○ 例如:仪器本身的误差、目标本身的噪声
○ 有尝试测量这些信息,但有很多困难
○ 2-2. 模型方差: 也称为第二次机会误差
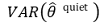
○ 由于样本组是从总体中随机提取的集合而导致的机会误差
○ 原因:过度拟合
○ 解决方案:使用更简单的模型
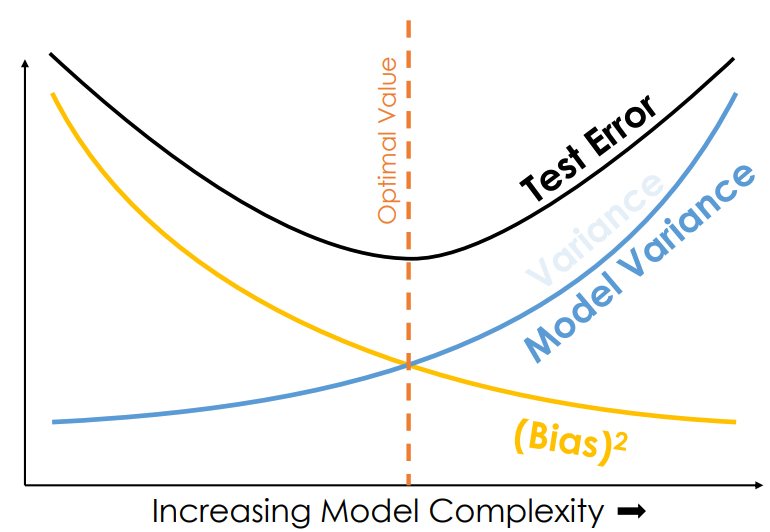
○ 偏差-方差权衡:随着模型复杂度的增加,偏差减小,但模型方差增大,从而产生权衡关系和最优复杂度
 </中心>
</中心>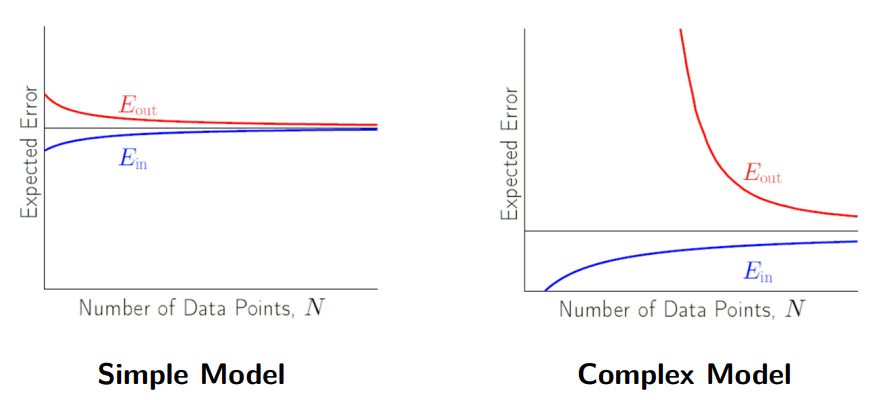
○ BLUE(最佳线性无偏估计量):线性无偏估计量中方差最小的估计量
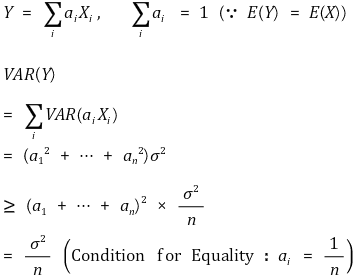 </中心>
</中心>○ 均匀最小方差无偏估计量 (UMVU)
○ 定义: 无偏估计量(包括非线性无偏估计量)中方差最小的估计量
○直接计算Fisher信息In
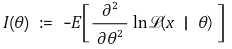 </中心>
</中心>○ Fisher信息In的间接计算
○ Cramér–Rao 下限 = 1 / In
○ 如果估计量等于 Cramér–Rao 下界,则为 UMVU
○ 示例 1. 样本均值和样本中位数
○ 总体分布呈正态时样本均值的渐近分布
○ 总体分布呈正态时样本中位数的渐近分布
»> ○ 当总体分布呈正态时,Hodges-Lehmann 估计量(定义为中位数 [(Xi + Xj) / 2 : i ≤ j])比样本均值更有效。
○ 如果随机变量服从双指数分布,则样本均值的方差大于样本中位数。
○ 示例 2. 样本标准差 (Sn) 和 MAD(中值绝对偏差)
○ Sn →d σ
○ MAD = 中位数( X1 - μ , ⋯, Xn - μ ) →d Φ-1(3/4) σ = 0.676 σ
④ 标准 3. 一致性和一致估计量
○ 渐近性: 样本的特征,其大小接近于 Infini
○渐近无偏性:当n→∞时无偏性成立的情况。它与大数定律有关
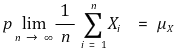 </中心>
</中心>○ 渐近效率
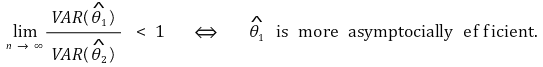 </中心>
</中心>○ 一致性:估计器收敛为参数的属性
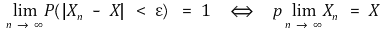 </中心>
</中心>○ X是一个随机变量,但通常被认为是一个特定的常数
○ 示例: 以下是一个较差的随机变量,因为它不一致
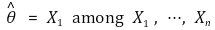 </中心>
</中心>○ ARE(渐近相对效率):两个随机变量的渐近方差之比。与理论值的显着偏差可能表明存在异常值。
⑤ 标准 4. 稳健估计量:研究估计量是否对异常值更敏感。
⑥ 标准 5. 最小二乘估计器
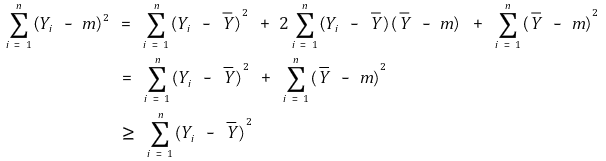
⑸ 方法1. 离散概率分布和最大概率
①它使用二项式系数的定义
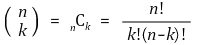
② 示例
○ 情况: 通过标记和重新捕获方法估算人口数量
○ 给定成员数N,首先捕获的成员数m,最后捕获的成员数n,最后标记的成员数x
○ 概率分布: 超几何分布
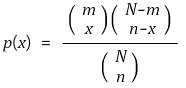
○问题: N最合理的取值
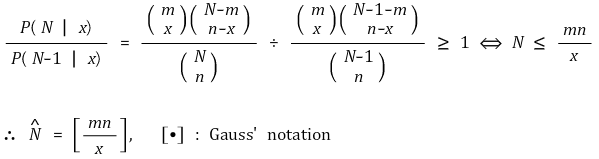 </中心>
</中心>⑹ 方法2.矩估计法(MOM):也叫样本模拟估计> ①定义:基于E(Xk) = g(θ) ⇔ θ = g-1(E(Xk))
○ E(Xk):矩或总体矩
○ (1/n) × ΣXik:样本时刻
○ 矩为常数,样本矩为常数分布的随机变量
○ 一致性:根据大数定律,样本矩收敛为矩
② 采样时刻
○ 原点的第 k 阶样本时刻
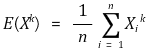
○ 样本均值的 k 阶样本矩
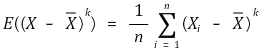 </中心>
</中心>③示例
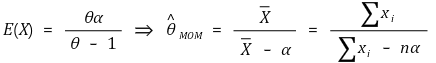
⑺ 方法3. 最大似然法(ML)
①定义
○ θ:参数
○ θ*: 参数 θ 的估计器
○ θML:参数θ的最大似然估计量
②可能性:某事发生的可能性
③似然函数
○ 当给定 θ* 时,给出给定样本的概率。
○ 也称为似然乘积
○ 即 p(X | θ*)
○标记为ℒ
④ 对数似然函数: 将对数代入似然函数
○ 标记为 ℓ = ln ℒ
⑤ 最大似然估计:检查使似然函数 p(X | θ) 最大化的 θML
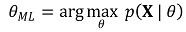
○ 假设: θ* 越接近参数 θ,似然函数越大
○ 第一第一。对数似然函数的微分:获取在有效区间上取得局部最大值的θ*
○ 第二第二。如果存在局部最大值:假设使得局部最大值的 θ* 为 θML
○ 第三第。如果局部最大值不存在:假设有效区间两端似然度较高的 θ* 为 θML
○最大似然估计和Hessian矩阵:获得所有可微函数估计量的有用方法
○ 步骤1. 通过获得 θk 的泰勒级数得到二阶近似,并计算使近似方程最大化的解 θk+1 = θk + dk
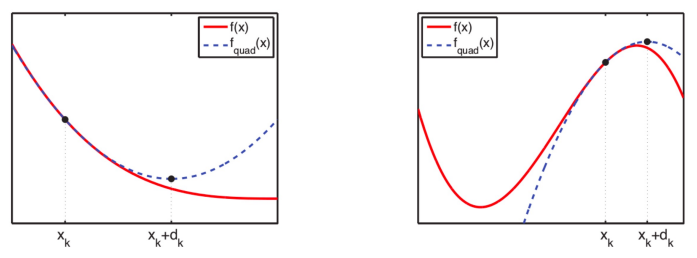
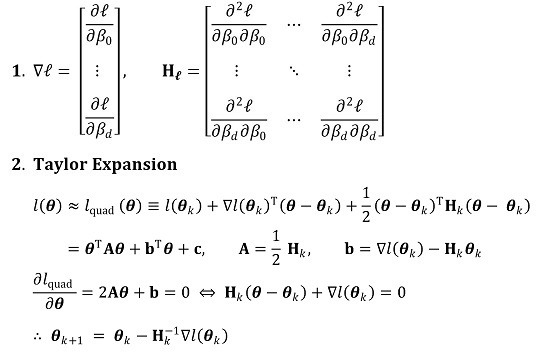
○ 步骤2. Newton-Raphson method: 更新θk最终将达到全局最大值
○ 示例:逻辑回归
⑥ 最大似然估计器:当给定样本X时,使似然最大化的θML对应的函数G » ○ θML = Gℓ (ℓ) = Gℒ(ℒ)
○ 估计器的限制: 最大似然估计的假设存在限制
○ 统计学家青睐的估计器。
⑦ MAP(最大后验)
○ 最大似然估计是【贝叶斯法则】的一个特例(https://jb243.github.io/pages/1623)

○ MLE 假设参数均匀分布,但当先验分布可用时,使用 MAP 方法。
⑧ 示例 1.
⑨ 示例 2.
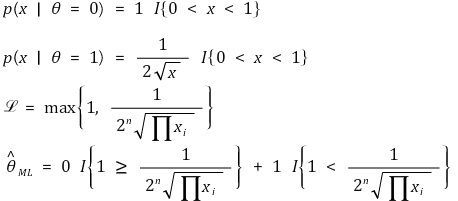
⑩ 示例 3.
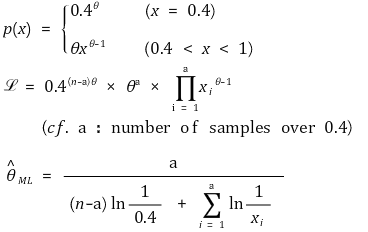 </中心>
</中心>⑪ 示例 4. 最大似然估计可能无法单独确定
 </中心>
</中心>⑫ 特点1.一致性
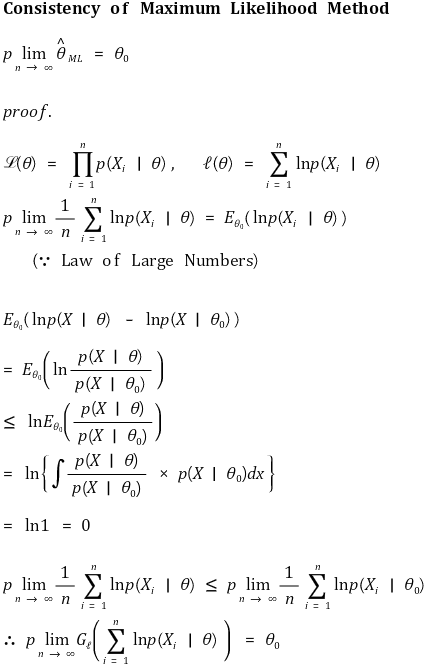 </中心>
</中心>⑬ 特征2.渐近正态分布

⑭ 特征3.不变性:如果θML 是θ的最大似然估计量,则g(θML)是g(θ)的最大似然估计量
3。区间估计(缩放类型)
⑴定义:通过样本估计参数处于哪个区间
①介绍目的:点估计器与实际参数完全匹配的概率为零
②置信水平(置信系数)
○ P(θ左 < θ < θ右) = 1 - α, 0 < α < 1
○ 阈值: 构成置信区间边界的值。 θ左、、θ右等
○ 1 - α:置信度(置信系数)
○ α:拒绝概率或显着性水平
○ 置信区间:区间 [θleft, θright] ,θ 位于其上的概率为 (1 - α) × 100%
③ 注释
○ P(Z > 1.65) = 5% ⇔ P(Z > 1.65) = 10%
○ P(Z > 1.96) = 2.5% ⇔ P(Z > 1.96) = 5%
○ P(Z > 2.58) = 0.5% ⇔ P(Z > 2.58) = 1%
④ 68 - 95 - 99.7 规则
○ μ ± 1 × σ: 68.27 %
○ μ ± 2 × σ: 95.45 %
○ μ ± 3 × σ: 99.73 %
⑵ 情况1. 当 Xi ~ N(μ, σ2) 和总体方差 σ2 已知时
①概述:使用正态分布
②方法
○介绍:当μ已知时,Xavg(置信度:α)的概率如下
</中心>
○ 想法改变: Xavg ε I (μ) ⇔ μ εI (Xavg) (置信度: α)
○ 含义:表示已知Xavg时μ的概率分布
○ 值得注意的是,当 μ 已知时,μ 的概率分布遵循与 Xavg 的概率分布相同的概念框架
○ 自己画图确认
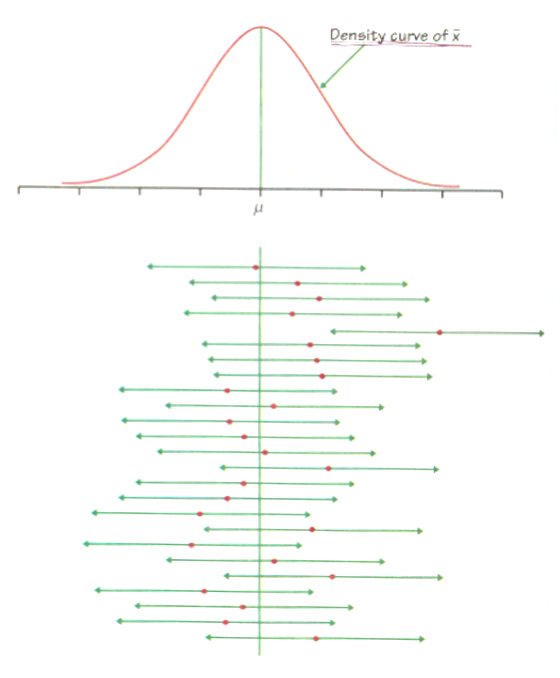 </中心>
</中心>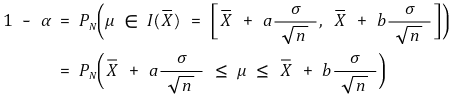
○ 关键估计:对于最短置信区间,应确定|a| = |b|,即 a = -zα/2,b = zα/2。这里省略证明
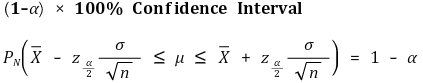
③ 如果你知道分布函数
○ 示例 1. F(x) = √x / θ, 0 ≤ x ≤ θ2:90% 置信区间如下

○ 示例 2. F(x) = (x / θ)n:90% 置信区间如下
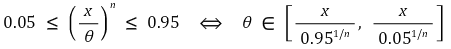
⑶ 情况2. 当 Xi ~ N(μ, σ2) 且总体方差 σ2 未知时
①概述
○ 正态分布需要知道总体的方差
○ 实际上,由于总体方差未知,因此使用样本方差
○ 当使用样本方差代替总体方差时,样本均值的分布恰好是t分布
② 示例 1. 样本均值
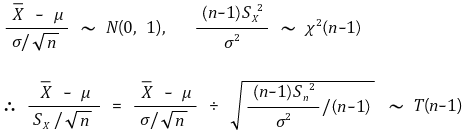
○介绍:当μ已知时,Xavg的概率(置信度:α)
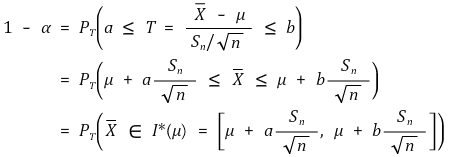
○ 想法改变:Xavg ε I* (μ) ⇔ μ ε I* (Xavg) (置信度:α)
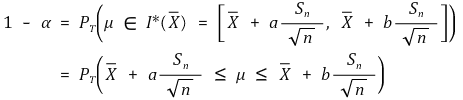 </中心>
</中心>○ 关键估计: 对于最短置信区间,应确定 |a| = |b|,即 a = - tα/2,b = tα/2。这里省略证明
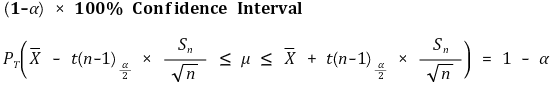
③ 示例2. (情况 1) 当 Xi (μX, σ2) (i = 1,…, n) 和 Yj (μY, σ2) (i = 1,…, n) 配对时
○ 也称配对估计(匹配样本估计)
○ 其实只有一个变量:定义Wi = Xi - Yi后,操作示例1
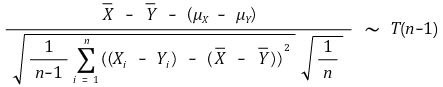
○ 配对样本示例

○ 独立样本示例
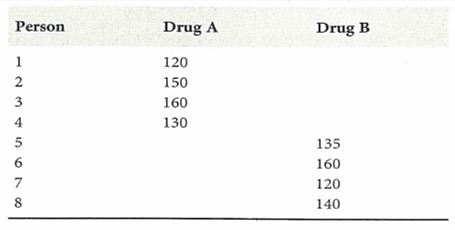
④ 示例 3.(情况 2) 两个样本均值的差异:当 Xi (μX, σ2) (i = 1, ···, n) 和 Yj (μY, σ2) (j = 1, ···, m) 独立时
○ 当非配对样本估计(合并样本估计)中两个样本均值的方差相同时
○ 公式
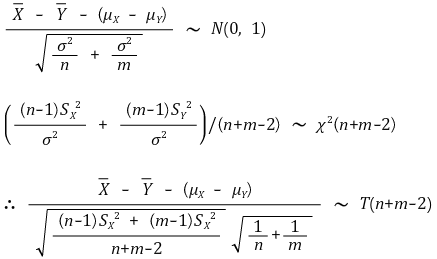
○ 置信水平 α 的置信区间
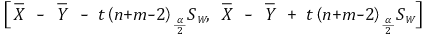
⑤ 示例 4.(情况 3) 样本平均值的差异: 当 Xi (μX, σX2) (i = 1, ···, n) 和 Yj (μY, σY2) (j = 1, ···, m) 是独立(假设 σX ≠ σY)
○ 当非配对样本估计(合并样本估计)中两个样本均值的方差不同时
○ 采用韦尔奇方法
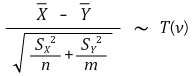
○ (情况 3) 的自由度低于 (情况 2) → 检验功效降低
○ ν 的公式很复杂
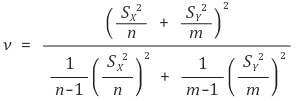
⑥ 示例 5. 总体方差的置信区间
○ 请注意,没有明显的解决方案可以最小化置信区间的大小: 应使用数值分析
○ 给定型号
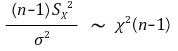 </中心>
</中心>○ 置信水平 α 的置信区间

> ⑦ 示例 6. 总体方差比
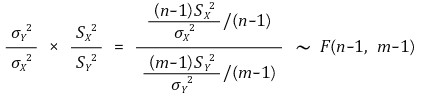
○ 置信水平 α 的置信区间
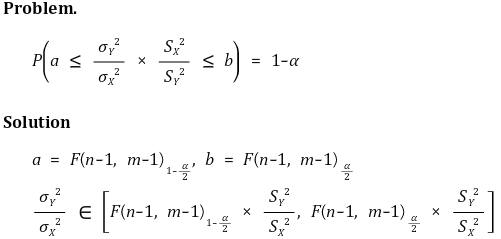
⑷ 情况3. 当样本不服从正态分布,但样本数量较多时
①【中心极限定理】(https://jb243.github.io/pages/1594#7-central-extreme-theorem):如果n足够大,样本均值的分布收敛为正态分布
○ 公式
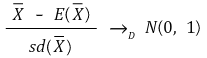 </中心>
</中心>○ t分布最终收敛为正态分布
②样品数量
○ 通常只需 25 ~ 30 个样本即可实现正态性
○ 对于对称单峰分布(具有一个极值),n = 5 就足够了
③ 示例1.人口比例
○ 给定型号
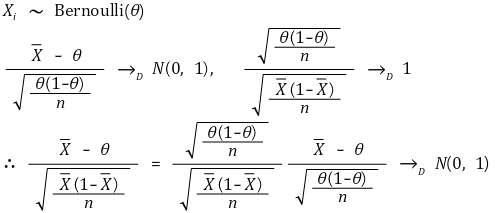 </中心>
</中心>○ 置信水平 α 的置信区间
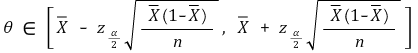 </中心>
</中心>④ 示例2.相关系数
○ 零假设 H0:相关系数 = 0
○ 备择假设 H1:相关系数 ≠ 0
○ t统计量的计算:为从样本中得到的相关系数r,
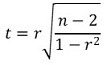
○ 上述统计量遵循自由度为 n - 2 的学生 t 分布(假设样本数为 n)
输入时间:2019.06.19 14:23