Chapter 11. Reinforcement Learning
Recommended Reading: 【Algorithm】 Algorithm Index
1. Overview
2. Markov Chain
a. Reinforcement Learning Problem Sets
1. Overview
⑴ Definition
① Supervised Learning
○ Data: (x, y) (where x is a feature, y is a label)
○ Goal: Compute the mapping function x → y
② Unsupervised Learning
○ Data: x (where x is a feature and there is no label)
○ Goal: Learn the underlying structure of x
③ Reinforcement Learning
○ Data: (s, a, r, s’) (where s is state, a is action, r is reward, s’ is the next state)
○ Goal: Maximize the total reward over multiple time steps
① Element 1. State
② Element 2. Reward
○ Definition: The change in the state.
○ Value function: The expected value of future rewards, expressed as lifetime value (VLT).
○ Formulation: For a state s, a policy π, and a discount factor γ that adjusts future value to present value.
○ Provides the basis for choosing an action by evaluating whether a state is good or bad.
③ Element 3. Action
④ Element 4. Policy
○ Definition: The agent’s behavior; a mapping that takes a state as input and outputs an action.
○ Decision process: A general framework for decision-making problems in which states, actions, and rewards unfold over a process.
○ Type 1: Deterministic policy
○ Type 2: Stochastic policy
○ Reason 1: In learning, the optimal behavior is unknown, so exploration is needed.
○ Reason 2: The optimal situation itself may be stochastic (e.g., rock–paper–scissors, or when an opponent exploits determinism).
⑤ Element 5. Model
○ Definition: The behavior/dynamics of the environment.
○ Given a state and an action, the model determines the next state and the reward.
○ Note the distinction between model-free and model-based methods.
⑶ Characteristics: Different from supervised learning and unsupervised learning
① Implicitly receives correct answers: Provided in the form of rewards
② Needs to consider interaction with the environment: Delayed feedback can be an issue
③ Previous decisions influence future interactions
④ Actively gathers information: Reinforcement learning includes the process of obtaining data
2. Markov Chain
⑴ Overview
① Definition: A system where the future state depends only on the current state and not on past states
② A Markov chain refers to a Markov process whose state space is finite or countably infinite.
③ Lemma 1. Chapman-Kolmogorov decomposition
④ Lemma 2. Linear state-space model
① Strongly Connected (= Irreducible): A state where any node i in the graph can reach any other node j
② Period: The greatest common divisor of all paths returning to node i
○ Example: If two nodes A and B are connected as A=B with two edges, the period of each node is 2
③ Aperiodic: When all nodes have a period of 1
○ Aperiodic ⊂ Irreducible
○ Example: If each node has a walk returning to itself, it is aperiodic
④ Stationary State: If $Pr(x_n \mid x_{n-1})$ is independent of $n$, the Markov process is stationary (time-invariant)
⑤ Regular
○ Regular ⊂ Irreducible
○ If there exists a natural number k such that all elements of the k-th power of the transition matrix M^k are positive (i.e., nonzero)
⑥ Lemma 1. Perron-Frobenius theorem
⑦ Lemma 2. Lyapunov equation
⑧ Lemma 3. Bellman equation
⑵ Type 1. Two-State Markov Chain
Figure 1. Two-Scale Markov Chain
① M: Transformation causing state transition in one step
② Mn: Transformation causing state transition in n steps
③ Steady-State Vector: A vector q satisfying Mq = q, i.e., an eigenvector with eigenvalue 1
⑶ Type 2. HMM (Hidden Markov Model)
① χ = {Xi} is a Markov process and Yi = ϕ(Xi) (where ϕ is a deterministic function), then y = {Yi} is a Hidden Markov Model.
② Baum-Welch Algorithm
○ Purpose: Learning HMM parameters
○ Input: Observed data
○ Output: State transition probabilities and emission probabilities of HMM
○ Principle: A type of EM (Expectation Maximization) algorithm
○ Formula
○ Akl: Number of transition from state k to l
○ Ek(b): Number of emissions of observation b from state k
○ Bk: Initial probability for state k
○ Purpose: Find the most likely hidden state sequence given an HMM
○ Input: HMM parameters and observed data
○ N: Number of possible hidden states
○ T: Length of observed data
○ A: State transition probability, akl = probability of transitioning from state k to state l
○ E: Emission probability, ek(x) = probability of observing x in state k
○ B: Initial state probability
○ Output: Most probable state sequence
○ Principle: Uses dynamic programming to compute the optimal path
○ Step 1. Initialization
○ bk: Initial probability of state $k$, $P(s_0 = k)$
○ $e_k(σ)$: Probability of observing the first observation σ in state $k$, $P(x_0 \mid s_0 = k)$
○ Step 2. Recursion
○ Compute maximum probability from the previous state at each time step i = 1, …, T
○ Compute backpointer (ptr) storing the most probable previous state
○ ptri(l) serves to store the previous state k that has the highest probability of transitioning to the current state l.
○ Step 3. Termination
○ Select the highest probability at the final time step
○ Determine the last state of the optimal sequence
○ vk(i - 1): Optimal probability at previous time step i - 1 in state k
○ akl: Probability of transitioning from state k to l
○ Step 4. Traceback
○ Trace back through ptr array from i = T, …, 1 to recover the optimal path
○ Example
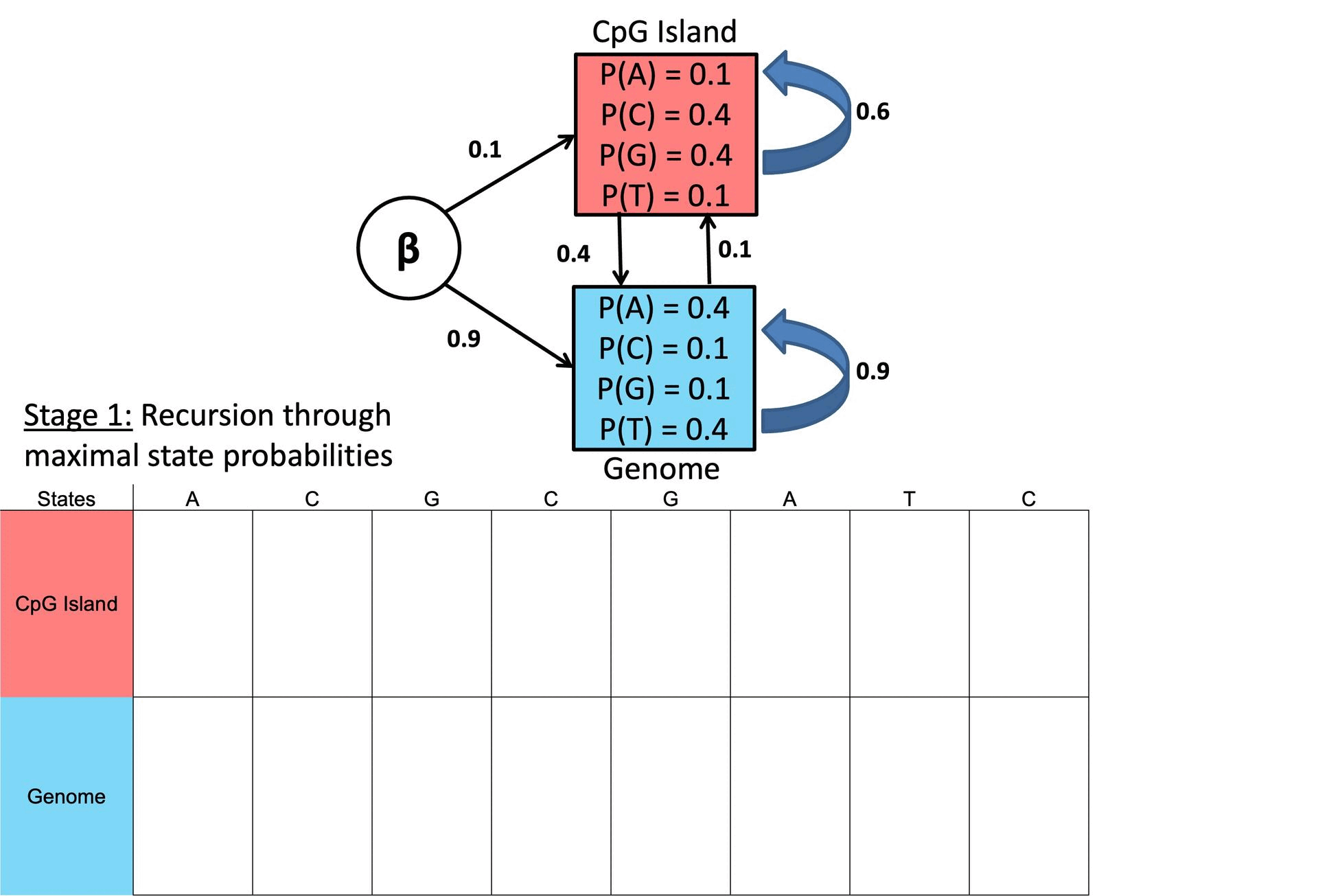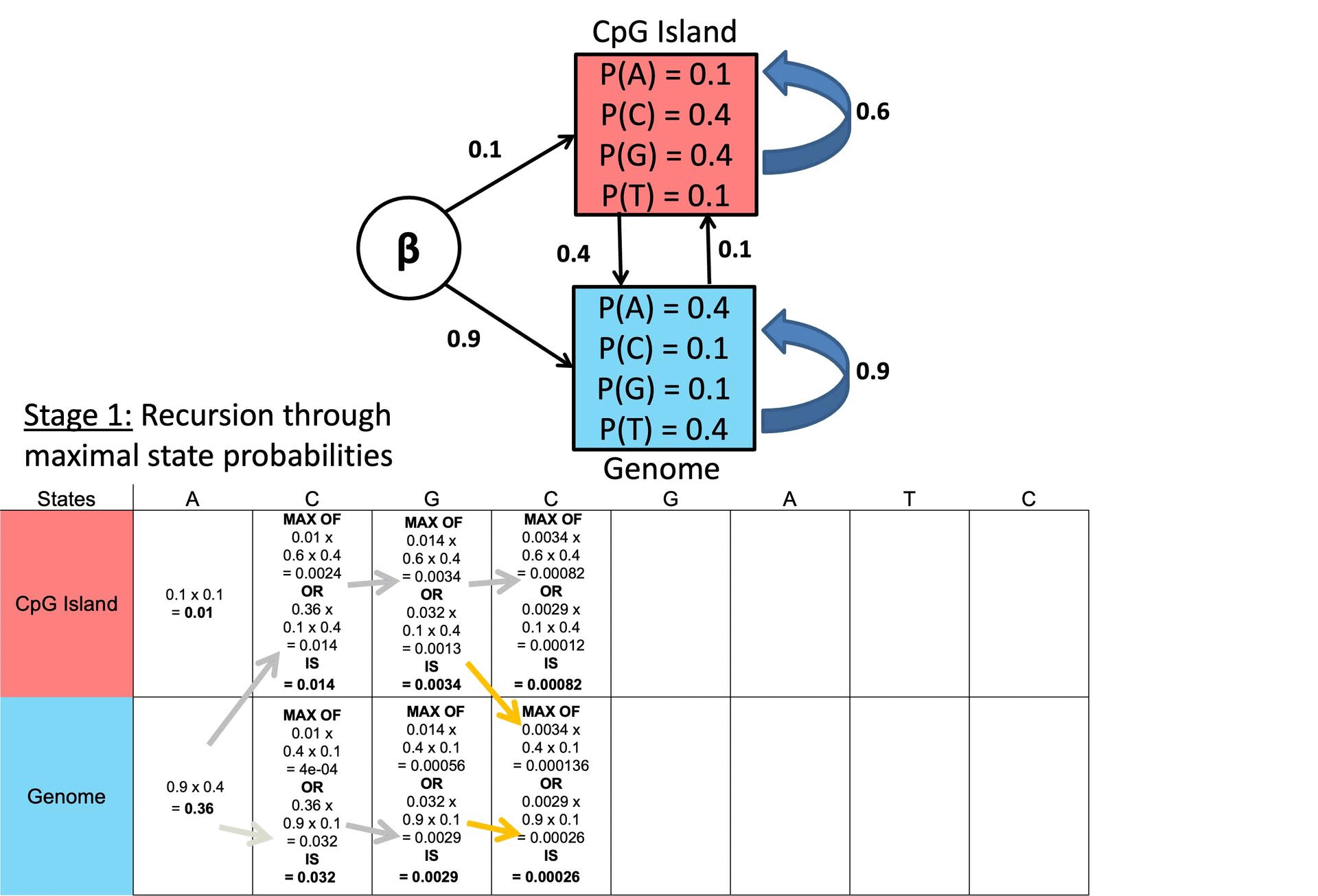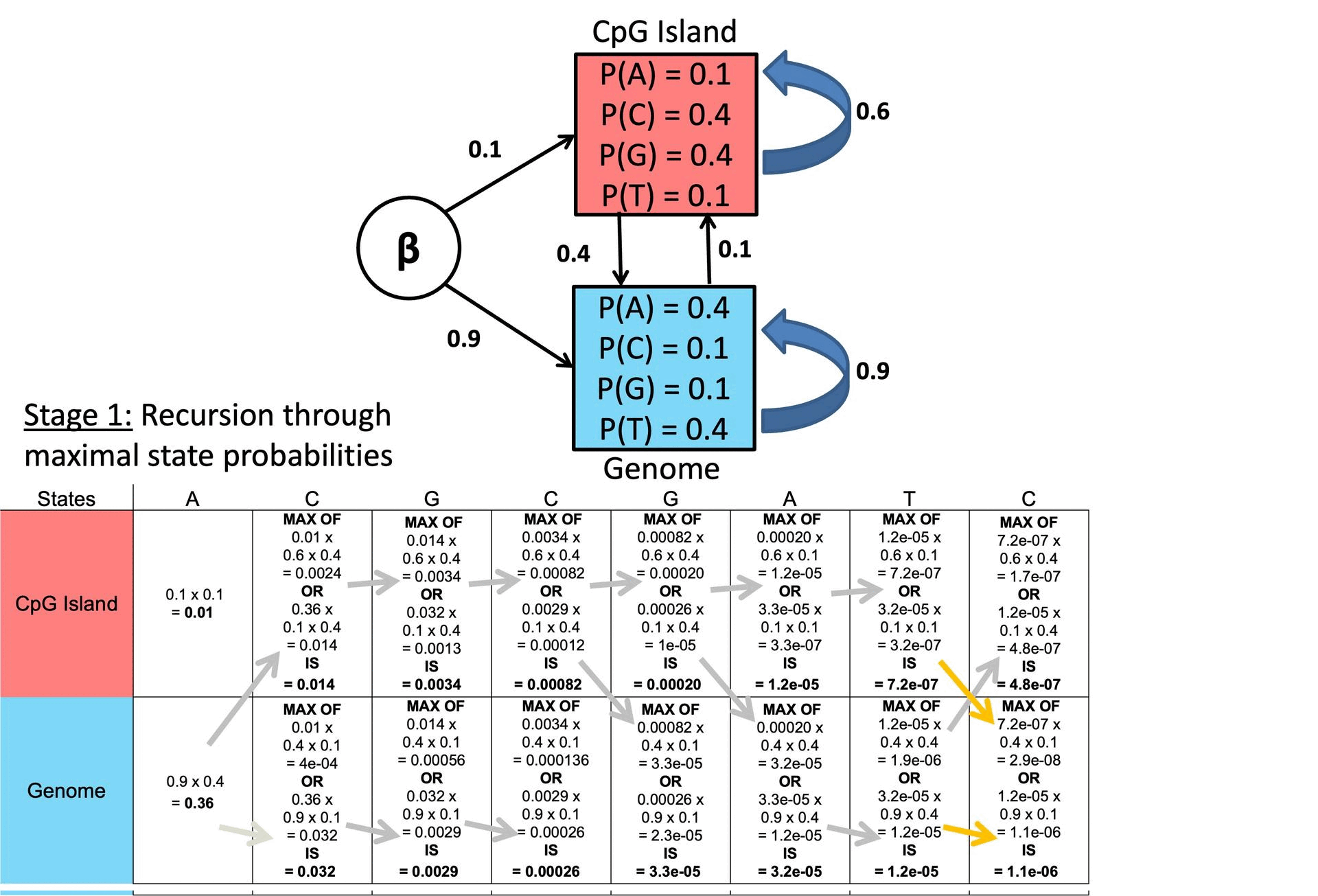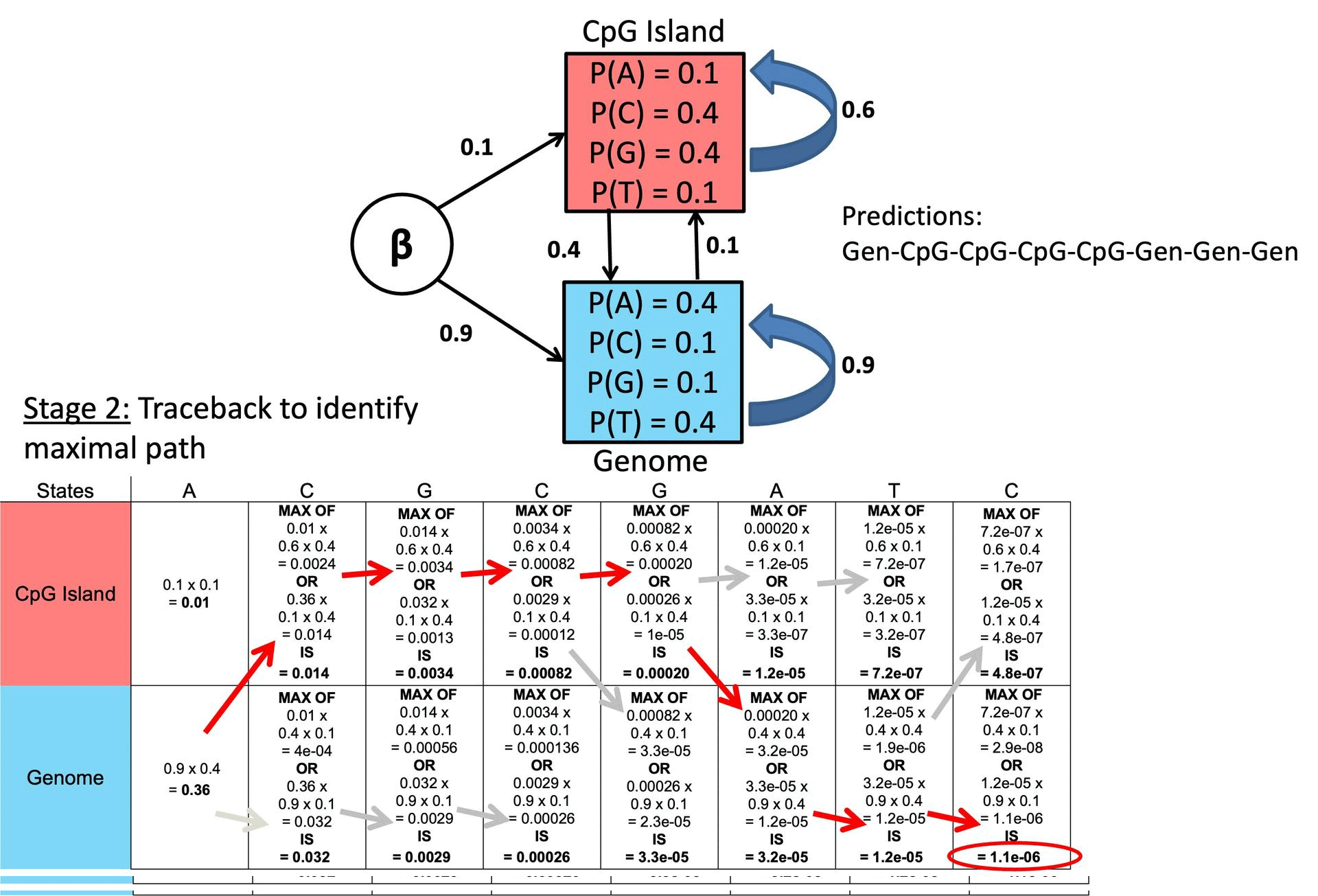
Figure 2. Example of Viterbi Algorithm
○ Python Code
class HMM(object):
def __init__(self, alphabet, hidden_states, A=None, E=None, B=None):
self._alphabet = set(alphabet)
self._hidden_states = set(hidden_states)
self._transitions = A
self._emissions = E
self._initial = B
def _emit(self, cur_state, symbol):
return self._emissions[cur_state][symbol]
def _transition(self, cur_state, next_state):
return self._transitions[cur_state][next_state]
def _init(self, cur_state):
return self._initial[cur_state]
def _states(self):
for k in self._hidden_states:
yield k
def draw(self, filename='hmm'):
nodes = list(self._hidden_states) + ['β']
def get_children(node):
return self._initial.keys() if node == 'β' else self._transitions[node].keys()
def get_edge_label(pred, succ):
return (self._initial if pred == 'β' else self._transitions[pred])[succ]
def get_node_shape(node):
return 'circle' if node == 'β' else 'box'
def get_node_label(node):
if node == 'β':
return 'β'
else:
return r'\n'.join([node, ''] + [
f"{e}: {p}" for e, p in self._emissions[node].items()
])
graphviz(nodes, get_children, filename=filename,
get_edge_label=get_edge_label,
get_node_label=get_node_label,
get_node_shape=get_node_shape,
rankdir='LR')
def viterbi(self, sequence):
trellis = {}
traceback = []
for state in self._states():
trellis[state] = np.log10(self._init(state)) + np.log10(self._emit(state, sequence[0]))
for t in range(1, len(sequence)):
trellis_next = {}
traceback_next = {}
for next_state in self._states():
k={}
for cur_state in self._states():
k[cur_state] = trellis[cur_state] + np.log10(self._transition(cur_state, next_state))
argmaxk = max(k, key=k.get)
trellis_next[next_state] = np.log10(self._emit(next_state, sequence[t])) + k[argmaxk]
traceback_next[next_state] = argmaxk
trellis = trellis_next
traceback.append(traceback_next)
max_final_state = max(trellis, key=trellis.get)
max_final_prob = trellis[max_final_state]
result = [max_final_state]
for t in reversed(range(len(sequence)-1)):
result.append(traceback[t][max_final_state])
max_final_state = traceback[t][max_final_state]
return result[::-1]
④ Type 1. PSSM: Simpler HMM structure
⑤ Type 2. Profile HMM: It is advantageous over PSSMs regarding the following:
○ Diagram of profile HMM
Figure 3. Diagram of profile HMM
○ M, I, and D represent match, insertion, and deletion, respectively.
○ Mi can be transitioned to Mi+1, Ii, and Di+1.
○ Ii can be transitioned to Mi+1, Ii, and Di+1.
○ Di can be transitioned to Mi+1, Ii, and Di+1.
○ Advantage 1. The ability to model insertions and deletion
○ Advantage 2. Transitions are restricted only between valid state traversal.
○ Advantage 3. Boundaries between states are better defined.
⑸ Type 3. Markov chain Monte Carlo (MCMC)
① Definition: A method for generating samples from a Markov chain following a complex probability distribution
② Method 1. Metropolis-Hastings
○ Generate a new candidate sample from the current state → Accept or reject the candidate sample → If accepted, transition to the new state
③ Method 2. Gibbs Sampling
④ Method 3. Importance/Rejection Sampling
⑤ Method 4. Reversible Jump MCMC
○ General MCMC methods like Method 1 and Method 2 sample from a probability distribution in a fixed-dimensional parameter space
○ Reversible Jump MCMC operates in a variable-dimensional parameter space: The number of parameters dynamically changes during sampling
3. Markov Decision Process
⑴ Overview
① Definition: A decision process in which the future depends only on the current state.
② In practice, the vast majority of problem settings can be treated as a Markov decision process (MDP).
③ Schematic: For transitions, the state at t+1 is determined solely as a function of the state at t.
Figure 4. Agent-Environment Interaction in MDP
○ State: $s_t ∈ S$
○ Action: $a_t ∈ A$
○ Reward: $r_t ∈ R(s_t, a_t)$
○ Policy: $a_t ~ π(· \mid s_t)$
○ Transition: $(s_{t+1}, r_{t+1}) ~ P(· \mid s_t, a_t)$
④ Existence of optimal solution $V(s)$
○ Premise 1. Markov property
○ Premise 2. Stationary assumption
○ Premise 3. No distributional shift
⑵ Type 1. Model-based algorithm
① Definition: if transition kernel is known
② 1-1. Value iteration
③ 1-2. Policy iteration
⑶ Type 2. Q-learning
① Q-learning (Watkins, 1989)
○ Overview
○ Learn the Q-function (action-value function) directly from data.
○ Model-free (off-policy), i.e., the transition dynamics $P(x’ \mid x, u)$—is unknown.
○ The reward function $R(s, a)$ is known.
○ Example of value iteration.
○ Formula: Because the next state $j$ is fixed, the transition probability term drops out.
○ Step 1. Initialize estimates for all state/action pairs: Q̂(x, u) = 0
○ Step 2. Take a random action $u$
○ Step 3. Observe the next state $x’$ and receive $R(x’, u)$ from the environment: Note that this is the realized reward, not the expected reward.
○ Step 4. Update $Q̂(x, u)$
○ Supplements
○ Learning the full model requires $\left|\mathcal{S}\right|^2\left|\mathcal{A}\right|$ memory, but Q-learning only needs $\left|\mathcal{S}\right|\times\left|\mathcal{A}\right|$ memory.
○ It is also referred to as TD (temporal-difference) learning.
○ Proof on convergence of Q-learning: Pseudo-contraction mapping
② Average-reward Q-learning
③ SARSA (State-Action-Reward-State-Action; ε-greedy, epsilon greedy) (Rummery & Niranjan, 1994)
○ Overview
○ On-policy: the target policy and the bahavior policy are the same.
○ When there is no data available, it chooses a policy and collects new data through interaction with the environment.
○ Formula
○ Step 1. Initialize estimates for all state/action pairs: Q̂(s, a) = 0
○ Step 2. At each step $k$, with probability 1 - εk, take u ∈ arg maxv Q̂(x, v); with probability εk, take a random action
○ Step 3. Observe the next state $x’$ and receive $R(x’, u)$: Note that this is the realized reward, not the expected reward.
○ Step 4. Update Q̂(x, a)
○ Step 5. As $k \to \infty$, drive $\varepsilon_k \to 0$; in this case, one can also use a Boltzmann (softmax) distribution with temperature annealing $(T \to 0)$.
○ Comparison with Q-learning
○ Target policy: the policy to be learned
○ Behavior policy: the policy used to generate samples
○ Q-learning: target policy = optimal policy; behavioral policy = any policy under which each action is taken infinitely often
○ SARSA: target policy = ε-greedy policy; behavioral policy = ε-greedy policy
○ Supplement 1. Using an ε-greedy behavior policy doesn’t automatically make it SARSA; what matters is the target policy used in the update.
○ Supplement 2. “Off-policy” means that no matter which policy collected the data, the update uses a greedy target (i.e., the max over next actions).
○ Supplement 3. If the behavior policy is fully greedy (ε = 0), then in SARSA $a’ = \arg\max_{a} Q(s’, a)$, so the targets match and the update equations become essentially the same between Q-learning and SARSA.
④ Q-learning with Linear Function Approximation
○ Purpose: The memory space of Q-learning is ㅣ𝒮ㅣ × ㅣ𝒜ㅣ, while that of linear function approximation is M ≪ ㅣ𝒮ㅣ × ㅣ𝒜ㅣ.
○ Formula: Note that δk2, which is the squared temporal difference, is always non-negative.
○ Significance: With a fixed policy and on-policy sampling, convergence is guaranteed (in an appropriate sense). At the convergence point, the Bellman error itself is not necessarily zero, but when that Bellman error is projected onto the feature space, it becomes zero.
○ Example: Tetris game (code)
○ Problem: If those conditions are violated (e.g., off-policy learning or updating with incorrect weighting), the algorithm can diverge. The following is an example where a problem occurs because the Bellman operator is based on policy $\mu$, but the sample distribution used for the update is not the stationary distribution of $\mu$.
⑷ Type 3. DQN
① Q-learning with nonlinear function approximation
○ Formula: Constructs loss function based on Bellman equation.
○ Problem: Local optima, Unstability during training
② Experience Replay (Replay Buffer)
Figure 5. Replay buffer and experience replay
○ Definition: A replay buffer is a memory that stores the agent’s past experiences collected from the environment. A single time-step transition is usually stored as $(s, a, r, s’, \text{done})$.
○ Motivation: In reinforcement learning, data arrive as a sequence $(y_1,(x_1,u_1)) \rightarrow (y_2,(x_2,u_2)) \rightarrow (y_3,(x_3,u_3)) \rightarrow \cdots$, so samples are highly correlated and the data distribution keeps changing. Deep learning (SGD) is typically much more stable when samples are i.i.d. (independent and identically distributed). With highly correlated data, updates can “swing” in one direction, often leading to divergence or oscillation during training.
○ How it’s used in training: Instead of updating the network using only the most recent experience, randomly sample a batch of transitions from the buffer and train the network on that mini-batch. This makes the training data closer to i.i.d., which helps improve stability and can reduce the chance of getting stuck in poor local solutions (i.e., improves training stability and robustness).
○ Experience replay stores states, not actions.
③ DQN (Deep Q-Network)
○ Definition: DQN implements Q-learning using deep neural networks. It is often implemented as an off-policy method.
○ Online network (Q-network): The network that is currently being trained. With parameters $\theta$, it outputs $Q(s,a;\theta)$. It is used both for action selection (e.g., $\epsilon$-greedy) and is updated continuously via SGD.
○ Target network: A slowly changing copy of the online network. With parameters $\theta^-$, it outputs $Q(s,a;\theta^-)$ and is used to compute the target value $y = r + \alpha \max_{a’} Q(s’, a’; \theta^-)$. The target network is updated either by periodically copying the online parameters ($\theta^- \leftarrow \theta$, hard update) or by slowly tracking the online network, which stabilizes the targets.
○ While tabular Q-learning is guaranteed to converge, there is currently no theoretical guarantees on optimality and convergence of deep Q-learning algorithms.
○ Comparison with experience replay: Both aim to stabilize training, but they are different mechanisms.
○ Experience replay: Reduces sample correlation and distribution shift by shuffling data (making it closer to i.i.d.) through random sampling from a replay buffer.
○ DQN (target network mechanism): If the $Q$ used to compute the target $y = r + \alpha \max Q(s’, a’)$ changes too rapidly, training can diverge. The target network updates slowly, reducing the “moving target” problem and improving stability.
○ SGD detail: To treat $y_k$ as a label, DQN ignores the fact that $y_k$ is actually a function of the network parameters $w$.
○ Mini-batch SGD: Training is typically performed using mini-batches sampled from the replay buffer.
○ Implementation in Pytorch
Figure 6. Implementation in Pytorch
○ Left (alternative form):
forward(state, action) -> q_scalarwith shape(batch, 1). A drawback is that you must evaluate all possible actions separately—i.e., run multiple forward passes to compute $Q(s,1), Q(s,2), \ldots$ and then compare them.
○ Right (standard DQN form):
forward(state) -> q_valueswith shape(batch, num_actions). Since you only need a single forward pass and then takeargmax, action selection is simple and computationally efficient. Also, because the early hidden layers are shared, the learning signal for one action can change the shared representation and indirectly affect the Q-values of other actions (i.e., coupling).
random.sample(self.replay buffer, batch size)
next state values = target net(next states).max(1)[0]
target values= rewards + gamma × next state values.detach()
loss = nn.MSELoss()(state action values, target values)
optimizer.zerograd(); loss.backward(); optimizer.step()
○ Applications: Applied to many games (e.g., Cartpole Problem (code), Atari 2600 (2013), AlphaGo (2016), etc.).
④ DDQN(double Q-learning)
○ Thrun and Schwartz (1993): Q-learning often overestimates the action value (Q-value) under certain states. Because the same network makes choices and evaluations at the same time. That is, it is related to the fact that the target in Q-learning includes $\max_v Q(x_{k+1}, v)$.
○ Double Q-learning (van Hasselt, 2010)
○ Definition: Using two Q-functions, parameterized by $w$ and $w’$, one function — the online network — selects the action, while the other — the target network — evaluates the value of that action. By separating selection and evaluation in this way, overestimation caused by the max operation can be reduced.
○ Principle: Double estimator is underestimator.
○ Formula
○ Q-learning vs. Double Q-learning (Weng et al., 2020): In Q-learning, the learning rate is $\beta_k = \frac{c}{k}$, whereas in Double Q-learning it is $\beta_k = \frac{2c}{k}$. Under linear function approximation, we can obtain the following. This also implies that Double Q-learning can converge faster because it uses a larger learning rate.
○ Example: DQN overestimation and DDQN in JAX (code)
○ Clipped double Q-learning (Fujimoto, van Hoof, David Meger, 2018)
○ Definition: Taking the minimum of two Q-values helps mitigate the overestimation bias in Q-learning.
⑤ Dueling DDQN (Wang et al, 2016)
Figure 7. Dueling DDQN
○ Definition: For the advantage function $A(s,a):=Q(s,a)-V(s),$ we build a model that predicts \(V\) and \(A\) separately using \(Q(x,u;w,w_v,w_a)=V(x;w,w_v)+A(x,u;w,w_a),\) and then combine them afterward.
○ Motivation: Except for the optimal action, not every action is equally important. \(A(s,a)\) can contrast actions under the same state \(s\).
○ Unidentifiability problem: The decomposition is not unique because \(Q(s,a)=V(s)+A(s,a)=(V(s)+c)+(A(s,a)-c),\quad c\in\mathbb{R},\) so infinitely many \((V,A)\) pairs yield the same \(Q\).
○ Solution 1 (Subtract max): \(Q(x,u;w)=V(x;w)+\big(A(x,u;w)-\max_v A(x,v;w)\big).\) Under a greedy policy, \(Q(x,a^*)=V(x),\) so it enforces the advantage to be \(0\) for the selected optimal action.
○ Solution 2 (Subtract mean): \(Q(x,u;w)=V(x;w)+\left(A(x,u;w)-\frac{1}{\left\|\mathcal{A}\right\|}\sum_v A(x,v;w)\right).\)
○ Pros: Improves optimization stability; resolves the unidentifiability issue.
○ Cons: With subtract-mean, \(V\) becomes a different baseline (the average \(Q\)) rather than \(V^*\), so the semantics of \(V\) and \(A\) no longer match the original \(V^*\) and \(A^*\) definitions.
○ Example: CartPole (code)
⑥ Multi-step target (Sutton & Barto, 1998)
○ \(Q(x_k,u_k)=\mathbb{E}[r(x_k,u_k)] + \alpha, r(x_{k+1},\pi^*(x_{k+1}))+\cdots+\alpha^{n-1} r(x_{k+n-1},\pi^*(x_{k+n-1}))+\alpha^n \max_v Q(x_{k+n},v).\)
○ SARSA with a multi-step target (sliding-window style): Use the loss function \(\big(r_k^{(n)}+\alpha^n \max_v Q(x_{k+n},v;w)-Q(x_k,u_k;w)\big)^2.\)
⑦ Prioritized DDQN (Prioritized replay, Schaul et al., 2016)
○ Definition: Assign weights (priorities) to experiences using the information-theoretic concept of surprisal.
○ Step 1: When a new experience is added, assign it the maximum priority \(z_{\max}\).
○ Step 2: Using \(m\) experiences, compute the sampling probability \(p_k=\frac{z_k}{\sum_i z_i}.\)
○ Step 3: If experience \(k\) is sampled, define the update (change) in its weight \(z_k\) as follows:
⑧ Distributed DQN (Bellemare et al., 2017)
⑨ Noisy DQN
⑩ Deep O-network (DON)
⑪ Conclusion: Applying all of them will give you good performance
Figure 8. Rainbow
⑸ Type 4. Actor-critic
① Typical actor-critic
○ Definition: Generalized policy iteration. Learning policy π(s) directly
○ Motivation
○ In Q-learning, states can be continuous, but actions must be discrete
○ In policy gradient, both states and actions can be continuous
○ Typically DQN is used if there are dozens of action spaces, and policy gradient is used if there are more than that.
○ In DQN, the network takes \(x\) as input and outputs \(u\) (i.e., Q-values for each discrete action), whereas in actor–critic methods, the critic takes \(x\) and \(u\) as inputs and outputs \(Q(x,u)\) (because the action space is continuous/infinite).
○ Component 1. Critic
○ Evaluating current/improved policies or giving learning signals
○ Policy Evaluation: estimates the value of the current policy (Q-function in general in most cases).
○ TD(λ), double-Q, clipped double-Q
○ Component 2. Actor
○ The side that improves policy: a policy of action to reduce the difference between the goal and the present.
○ Policy Improvement: obtains a better policy based on the value of the current policy.
○ ε-greedy based on the current Q-function, policy-gradient.
○ Component 3. Parameterized policy: $\pi_w(u \mid x)$
○ An example process
○ Step 1. Receive frame
○ Step 2. Forward propagate to get P(action)
○ Step 3. Sample a from P(action)
○ Step 4. Play the rest of the game
○ Step 5. If the game is won, update in the ∇θ direction
○ Step 6. If the game is lost, update in the -∇θ direction
○ Type 1. On-policy actor-critic
○ The policy followed by the actor is the same policy used to collect data.
○ In other words, the behavioral policy is the same as the target policy.
○ Type 2. Off-policy actor-critic
○ The actor usually represents the target policy.
○ The data comes from a behavior policy, typically stored in a replay buffer or similar source.
○ The critic uses this data to learn the values needed to evaluate and improve the target policy.
② A3C (Asynchronous Advantage Actor-Critic)
③ Policy gradient theorem
○ $\rho_w$: Discounted state distribution (= geometric distribution, discounted occupancy measure)
○ $\nabla_w \log \pi_w(u \mid x)$: Score function
○ Gibbs policy:
○ Gaussian policy:
④ REINFORCE (Williams, 1988, 1992)
○ Use Monte Carlo methods to estimate the Q-function.
○ On-policy.
○ Drawback: high variance.
○ Example: CartPole (code)
⑤ Variance Reduction Theorem (Control Variates Method)
○ Definition: For a given $F(x)$, a variance reduction method that uses a function $\phi(x)$ satisfying $\mathbb{E}[\phi(x)] = 0$ and having high correlation with $F(x)$, in order to reduce the variance of $\mathrm{Var}(F(x) - \phi(x))$.
○ Application in the policy gradient theorem
○ $G_w(x_k)$ must be action-independent. It may depend on $x_{k-1}$, but if it depends on $x_{k+1}$, it implicitly contains information about $u_k$, which makes it inappropriate.
⑥ Natural Policy Gradient (NPG)
○ Policy gradient theorem is a kind of optimization algorithm: Euclidean. Maximum, minimum in ±∞ without quadratic terms.
○ NPG (Kakade et al., 2001)
○ Convergence of PG (Mei et al., 2020): under the tabular setting where the state and action sets are finite,
○ $\beta = (1-\alpha)^3 / 8$
○ $S$: the number of states. Since it is typically very large, it becomes an issue in convergence arguments for PG.
○ $\rho$: the discounted state distribution
○ $c$: a constant
○ $d$: the distribution of the initial condition
○ Convergence of NPG (Agarwal, 2020): under the tabular setting where the state and action sets are finite,
○ $\beta = (1-\alpha)^2 \log \left|\mathcal{A}\right|$
○ $t$: the iteration index (number of iterations)
○ NPG + entropy regularization
○ The policy $\pi$ is usually set as follows:
○ If we set $\beta = (1-\alpha)/\tau$, then the above policy becomes soft policy iteration ($\simeq$ a softmax policy).
○ As $\tau \to 0$, soft policy iteration reduces back to standard policy iteration.
⑦ TRPO(trust region policy optimization)
○ Performance difference lemma (Kakade & Langford, 2002)
○ Local approximation
○ TRPO (Schulman et al., 2015)
○ TRPO = NPG with a different learning rate.
○ $\tilde{\beta}$ is chosen with a backtracking line search to satisfy the constraint.
○ The KL divergence constraint prevents the policy from changing too quickly.
○ Monotonic improvement theorem: With carefully chosen learning rates, TRPO guarantees that under general function approximations $V_{w_{k+1}}(x_0) ≥ V_{w_k}(x_0)$.
⑧ Proximal Policy Optimization (PPO)
○ Rationale: NPG and TRPO require computing the inverse of the Fisher information matrix (i.e., they are second-order methods), which makes them computationally expensive.
○ PPO: First-order method
○ PPO-CLIP (clipped PPO): Uses a min operation to conservatively discourage how much the model changes. The proportional coefficient in the second term is clipped so that if it deviates from 1 by more than $\epsilon$, it is set to $1 \pm \epsilon$.
⑨ Deterministic Policy Gradient (DPG)
○ Now considers deterministic policy $\mu_\theta(x)$ instead of stochastic policy $\pi_w(u \mid x)$.
○ In SPG, the derivative is $\nabla_\theta \pi_\theta(u \mid x)$, which describes how the probability of a specific action changes when the policy parameter $\theta$ changes.
○ In DPG, the derivative is $\nabla_u Q(x,u)$, which describes how $Q$ changes when the action value $u$ is slightly moved.
○ Unlike SPG, DPG uses a policy that outputs the action value itself rather than a probability distribution. Therefore, the differentiation path changes to $\theta \rightarrow \mu_\theta(x) \rightarrow Q$.
○ Off-policy DPG
○ Deep DPG (DDPG): The loss function is defined as follows, and backpropagation is performed.
○ Twin Delayed DDPG (TD3) (Fujimoto, van Hoof, Meger, 2018): Clipped double-Q (= twin) + DPG
def train(self, cur_time_step, episode_time_step, state, action, reward, next_state, done):
self.add_to_replay_memory(state, action, reward, next_state, done)
if len(self.replay_memory_buffer) < self.batch_size:
return
if cur_time_step % self.update_every != 0:
return
for it in range(self.update_every):
mini_batch = self.get_random_sample_from_replay_mem()
state_batch = torch.from_numpy(np.vstack([i[0] for i in mini_batch])).float().to(self.device)
action_batch = torch.from_numpy(np.vstack([i[1] for i in mini_batch])).float().to(self.device)
reward_batch = torch.from_numpy(np.vstack([i[2] for i in mini_batch])).float().to(self.device)
next_state_batch = torch.from_numpy(np.vstack([i[3] for i in mini_batch])).float().to(self.device)
done_list = torch.from_numpy(np.vstack([i[4] for i in mini_batch]).astype(np.uint8)).float().to(self.device)
with torch.no_grad():
noise = torch.randn_like(action_batch) * self.target_noise
noise = torch.clamp(noise, -self.noise_clip, self.noise_clip)
next_action = self.actor_target(next_state_batch) + noise
next_action = torch.clamp(next_action, self.action_lower_bound, self.action_upper_bound)
target_Q1, target_Q2 = self.critic_target(next_state_batch, next_action)
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward_batch + self.gamma * (1.0 - done_list) * target_Q
current_Q1, current_Q2 = self.critic(state_batch, action_batch)
loss_crt = F.mse_loss(current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
self.crt_opt.zero_grad()
loss_crt.backward()
self.crt_opt.step()
if it % self.policy_delay == 0:
actor_action = self.actor(state_batch)
q1, q2 = self.critic(state_batch, actor_action)
loss_act = -q1.mean()
self.act_opt.zero_grad()
loss_act.backward()
self.act_opt.step()
self.soft_update_target(self.critic, self.critic_target)
self.soft_update_target(self.actor, self.actor_target)
○ It delivers strong performance.
○ Example: Bipedal Walker Problem (code)
⑩ Contrastive Reinforcement Learning (CRL)
○ Bayes optimal classifier
○ Type 1. GCRL(goal-conditioned reinforcement learning)
○ Premise
○ Approach 1. Bootstrapping / TD-learning: Goal in the state
○ Problem 1. Tabular $Q(s, a, g)$ has size ㅣ𝒮ㅣ×ㅣ𝒜ㅣ×ㅣ𝒢ㅣ, thus computational and sample complexity scale linearly in ㅣ𝒢ㅣ.
○ Problem 2. Unable to address the shared structure across $g$.
○ Approach 2. Occupancy-measure-based: Goal in the next state
○ In Approach 1, $\rho(g)$ is the goal-sampling prior, whereas in Approach 2, $\rho(g)$ serves as the negative/base distribution.
○ $Q^\pi(s,a,g) \neq Q_g^*(s,a)$
○ $Q^\pi(s,a,g)$: the probability of reaching goal $g$ when following the mixed policy currently in use.
○ $Q_g^*(s,a)$: how well the optimal policy dedicated solely to goal $g$ can reach $g$.
○ Example: Four Rooms Grid World
⑪ AlphaZero: An improvement on the AlphaGo model that relies on Go notation
Figure 9. AlphaZero
○ Overview
○ Search-based policy iteration
○ A kind of actor-critic.
○ Actor: Uses the policy network to perform Monte Carlo Tree Search (MCTS) and generate a better policy target.
○ Critic: Learns the state value using the results of self-play.
○ Step 1. In a single simulation, a fixed policy network provides a prior, and MCTS explores based on that prior.
○ At each state $s$, the branch corresponding to action $a$ has a Q-value $Q(s, a)$ and a visit count $N(s, a)$.
Figure 10. Structure of MCTS
○ Step 1-1. Choose the following action. The only point where the Q-value is used.
○ Step 1-2. When a newly encountered state or a terminal state is reached, the $Q$ and $N$ values along that path are updated. At this point, whether the value function is added or subtracted is determined by whether the final state corresponds to stones of the same color as mine. The value network helps guide the search and contributes to training stability.
Figure 11. Example of calculation
○ Steps 1–3. When a newly encountered state is reached, it is added to the tree, and $N(s_{\text{final}}, a) = Q(s_{\text{final}}, a) = 0$ for all $a$.
○ Step 2. From multiple simulation results, a better move distribution $\pi$ is obtained.
○ $\pi$ is a better policy target and made by MCTS (actor-like).
○ Example of calculation process
○ Step 3. After the actual game (self-play episode) ends, the final game outcome $z \in {-1, 0, +1}$ is obtained (critic-like).
○ In a standard actor-critic framework, the critic comes first and the actor updates the policy via policy gradients using the critic’s signal. In AlphaZero, by contrast, the actor comes first and the critic signal is obtained through self-play, so the order is reversed.
○ Since self-play data can be generated by past networks, it may, in a broad sense, come from policies different from the current network, which gives it an off-policy-like aspect.
○ Step 4. The network is trained on $(s, \pi, z)$. The value network is trained on $(s, z)$ pairs.
○ $\pi \log p$ is cross-entropy format.
○ By minimizing the loss function, the policy network learns a new policy $p_\theta(s_{h,k}) \approx \pi_{h,k}$ and the value of the new policy $v_\theta(s_{h,k}) \approx z_k$.
○ Pit the newly trained model (
self.nnet) against the previous model (self.pnet). If the new model performs well enough, accept it; otherwise, discard it.
○ Example: Play Othello Using AlphaZero
⑹ Type 5. Reward design
① Type 5-1. Reward shaping
○ Overview
○ In the case of sparse rewards, learning does not proceed properly.
○ For LLMs and similar models, it is difficult to define rewards.
○ Formulation: the reward shaping function $F$ is defined as follows.
○ Potential-based shaping function
○ $F(x, a, x’) = \alpha \phi(x’) - \phi(x)$, where $\phi$ is a potential function, such as a gravitational potential.
○ If $F$ is a potential-based shaping function, the optimal policy remains unchanged even after reward shaping.
② Type 5-2. RL with Human Feedback (RLHF)
○ Overview: The major problems with conventional reinforcement learning are as follows:
○ Reward misspecification
○ Reward hacking: for example, a robot may repeatedly perform trivial actions to gain bonuses instead of actually moving toward the goal.
○ Solution: RLHF
○ Example 1. GPT-3 (RL + PPO): pre-training (base model) → SFT (supervised fine-tuning) → RLHF
Figure 12. GPT3 RLHF Pipeline
○ Step 1. Make $\pi_\text{ref}$ with pre-training and SFT.
○ Step 2. Train the reward model.
○ Variables: prompt $x$, model response $y$
○ Problem definition: $s_t = (x, y_1, \cdots, y_t), a_t = y_{t+1}, \pi(y_{t+1}, s_t)$ (next token prediction), $r(s_t, a_t)$?
○ Reward is defined relatively: people prefer relative evaluation to absolute evaluation, and relative evaluation is more stable than absolute evaluation.
○ Bradley-Terry model (1952): Given two trajectories, $\tau_1$ and $\tau_2$ (each a prompt-response pair), it is assumed that humans have preferences as follows.
○ We can generate a reward model (neural network) $\hat{r}_{\phi}(x, y)$ that gives a scalar reward for a (prompt, response) pair. For the same question, $\tau_k^+$ and $\tau_k^−$ are two final answers, where one is preferred and the other is dispreferred.
○ Step 3. Use RL with PPO-CLIP.
○ PPO is typically easier to handle when rewards are provided at every step.
○ At the final token, the reward comes from the reward model’s final score.
○ For intermediate tokens, a KL penalty is applied to prevent the policy from deviating too far from the reference policy $\pi_ref$.
○ The cumulative reward from the current time step to the end (reward-to-go): the critic is typically trained to estimate this.
○ Example 2. DPO
Figure 13. DPO Pipeline
○ It is trained directly on human preference data without training a reward model, by making the chosen response more likely and the rejected response less likely.
○ For each prompt $x$, we view the problem as a bandit problem of deciding which arm to choose among multiple response candidates $y$.
○ When KL divergence is used as a regularizer, the optimal policy $\pi^*$ takes a very convenient form.
○ $\beta \downarrow$: more reward-seeking
○ $\beta \uparrow$: more conservative
○ Proof
○ Since the exact $r(x, y)$ is unknown, the loss function is defined as follows.
○ Comparison between RM+PPO and DPO
Table 1. Comparison between RM+PPO and DPO
○ Example: Half Cheetah
○ Example 3. Length-normalized DPO
○ Example 4. SimPO
○ Example 5. Zeroth-order policy optimization for RLHF: $x_{k+1} = x_k - h g_{\mu}(x_k; u_k)$
○ Example 6. SZPO(stochastic zeroth-order policy optimization): Has convergence
○ For each iteration $t = 1, \cdots, T$:
○ Step 1. Sample a random direction $v_t$ and form a perturbed policy $\theta_t’ = \theta_t + \mu_t v_t$.
○ Step 2. For each comparison $n = 1, \cdots, N$:
○ sample a batch of trajectories from $\pi_{\theta_t}$ (current policy);
○ sample a batch of trajectories from $\pi_{\theta’_t}$ (perturbed policy);
○ query $M$ human evaluators which batch is better and record $o_{t,n,m}$ ∈ {0, 1}.
○ Step 3. Aggregate to policy preference to find the improvement direction $\hat{g}_t=s_t v_t$.
○ Example: Half Cheetah
○ Example 7. Sign-SZPO: Has convergence
○ When preference model is unknown, we define $s_t = $Sign(𝔼[$r(\tau_{\theta’t}) - r(\tau{\theta_t})$]).
○ Reason for convergence: Dirction and sign have strong correlation coefficients.
③ Type 5-3. RL from Verifiable Rewards (RLVR)
○ Overview
○ Human annotation used in RLHF is expensive.
○ Some tasks admit automatic correctness checks like mathematical proof.
○ Objective function
○ Example 1. GRPO (Group Relative Policy Optimization)
○ Limitations of PPO
○ Example of a trajectory in an LLM: prompt → token1 → token2 → ··· → final answer
○ PPO aims to use an advantage for each token action, such as (A(s_1, a_1), A(s_2, a_2), \cdots)
○ In RLVR, the reward is only given at the very end: 1 if the whole answer is correct, and 0 if it is incorrect.
○ PPO is not well-suited for RLVR: since the RLVR reward is given only after the entire trajectory is completed, it is difficult to directly determine the contribution of each token/action. Estimating this requires a separate critic/value model or credit assignment.
○ Step 1. For each initial state, sample multiple outputs from the current policy: different trajectories generated from the same starting point.
○ Step 2. For each trajectory, obtain a verifiable reward using a verifier.
○ Step 3. Convert absolute rewards into group-relative advantages.
○ If the advantage of a response is higher/lower than the group average, increase/decrease the probabilities of all tokens that compose that response.
○ Comparing responses generated from the same initial state can partially offset differences in question difficulty.
○ Step 4. Objective function: similar to PPO.
○ Similarities: policy ratio, clipping, KL penalty
○ Difference: PPO obtains the advantage from a critic/value model, whereas GRPO constructs the advantage through relative comparison within the group.
4. General Decision Process
⑴ Multi-armed Bandit(MAB): UCB, Thompson Sampling, etc.
5. Advanced Topics
⑴ Unsupervised learning
① Benchmarks: URLB
② Baselines: Diversity is all you need, Forward Backward Representation
③ Envs: Dm_control, Maze, Hopper, Cheetah, Quadruped, Walker
⑵ Online goal-conditioned reinforcement learning
① Benchmarks: JaxGCRL
② Baselines: Contrastive Reinforcement Learning, SAC, PPO, TD3
③ Envs: Brax, Locomotion, Manipulation
⑶ Offline goal-conditioned reinforcement learning
① Benchmarks: OGBench
② Baselines: CRL, HIQL, QRL, implicit Q/V learning
③ Envs: Locomotion, Manipulation, powderworld
⑷ Continual reinforcement learning
① Benchmarks: CORA
③ Envs: Atari, Procgen, Minihack, CHORES, Nethack (codebase)
④ Envs without benchmark: AgarCL, Jelly Bean World
⑸ Open-ended reinforcement learning
① Benchmarks: Craftax baseline
③ Envs: Craftax
⑹ Safe reinforcement learning
① Benchmarks: Omnisafe
② Baselines: CPO, FOCOPS, PPO-Lagrangian and TRPO-Lagrangian
③ Envs: Safety-Gymnasium, Safe-Control-Gym
⑺ Multi-agent reinforcement learning
① Benchmarks: BenchMARL
③ Envs: PettingZoo, VMAS
⑻ Queueing network control via reinforcement learning
① Benchmarks: QGym
② Envs: DiffDiscreteEventSystem
Input: 2021.12.13 15:20
Updated: 2024.10.08 22:43