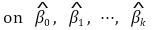第 16 章。线性回归分析
高级类别:【统计】【统计概述】(https://jb243.github.io/pages/1641)
1. 回归分析
2. 简单线性回归模型
3. 多元线性回归模型
a. R 中的回归分析
–
1. regression analysis
⑴回归分析:将某一特定变量表示为一个或多个其他变量的依赖关系
① 更准确地说,y ~ X(假设 y ∈ ℝ)
○ 包含在监督算法中
○ (注) 分类: y ~ X (assyming ㅣ { y } < ∞ )
○(注)Engression:虽然一般回归假设 Y = g(X) ± ε,但 engression 模型却是 Y = g(X + ε),这使得外推成为可能(其中 ε 是噪声)。
② 特定变量:名称因变量具有代表性,但有多个名称
○ Response variable
○ Outcome variable
○ 目标变量
○ Output variable
○ 预测变量
③其他变量:名称自变量具有代表性,但有多种名称
○ 实验变量
○ 解释变量
○ 预测变量
○ 回归器
○ Covariate
○ 控制变量
○ 调节变量
○ Exposure variable
○ Risk factor
○ Input variable
○ Feature
⑵(比较)交叉分析和方差分析
①回归分析:自变量是可测量变量。因变量是可测量变量
○ 回归分析显示自变量与因变量的因果关系
○ 不需要实际因果关系的证明,因为目的就是预测本身
○ 示例 : 6 岁儿童未钙化骨骼的长度可以预测身高的额外增长,但不是因果关系
②交叉分析:自变量是分类(分类)变量。因变量是分类(分类)变量
○ 交叉分析简单来说就是变量之间相关性的表示
③方差分析:自变量是分类(分类)变量。因变量是可测量变量
⑶一元回归分析和多元回归分析
①简单回归分析:具有一个自变量的回归
② 多元回归分析: 具有多个自变量的回归
⑷ 变量选择方法
① 正向选择
○ 步骤 1. 从仅包含截距的常量模型开始
○ 步骤 2. 依次添加对模型重要的自变量
② 后向淘汰法
○ 步骤 1. 从包含所有候选自变量的模型开始
○ 步骤 2. 从基于平方和影响最小的变量开始,一一删除变量
○ 步骤 3. 继续删除自变量,直到不再有统计上不显着的变量
○ 步骤4. 此阶段选择型号
③ 逐步法
○ 逐步添加:如果现有变量的重要性因添加新变量而减弱,则删除受影响的变量
○ 逐步消除:检查哪些变量被删除,当没有更多变量可以删除时停止
⑸ 选型标准
① 概述
○ 模型复杂度惩罚方法
○ 计算所有候选模型的AIC和BIC,选择值最小的模型
② AIC(赤池信息准则)» ○ AIC = -2 ln(L) + 2p(其中ln(L)是模型拟合,L是似然函数,p是参数数量)
○ 目的:由于参数多的模型容易过拟合,因此按参数数量的比例进行惩罚。
○ 显示实际数据分布与模型预测分布之间差异的指标
○ 值越低表示模型拟合越好
○ 随着样本量的增加,准确性会降低
③ BIC(贝叶斯信息准则)
○ BIC = -2 ln(L) + p ln n(其中ln(L)是模型拟合,L是似然函数,p是参数个数,n是数据点个数)
○ 随着样本量的增加,补偿 AIC 的不准确性
○ 随着样本量的增加,对更复杂的模型进行更严厉的惩罚
④ AICc
○ AICc = AIC + 2K(K+1) / (N-K-1),其中 N 是样本数
○ 目的:解决随着样本量增大,AIC 准确度降低的问题。
2.简单线性回归模型
⑴ 定义:简单回归分析的情况,其中依赖性显示为线性函数
⑵ 数据的表示
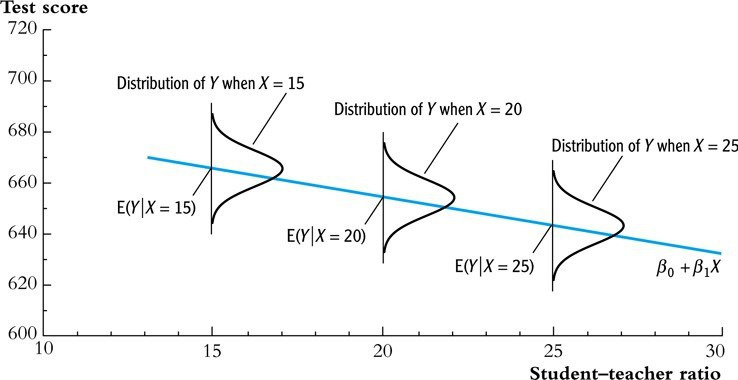
图 1. 简单线性回归模型
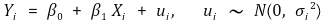
① β0 : y 截距
② β1 : X 上的斜率或系数
○ 也称为参数、回归系数、权重等
○ 直观上来说,弹性就是斜率绝对值大的程度
○ 在微观经济学中,弹性是指斜率乘以(-1)。
③回归线的类型
○ 总体回归线:根据总体特征得到的回归线
○拟合回归线:根据样本特征得到的回归线
④ ui : 残差
⑤残差与误差的区别
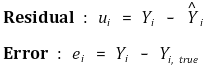
○ 后面提到的误差其实就是残差
⑥ 方差特征
○ 同方差: VAR(ui | Xi) 和 Xi 是独立的。一个不切实际的假设。许多统计程序的默认设置
○ 异方差性 **: VAR(ui | Xi) 取决于 Xi
○(注意)具有同方差性的模型是一个好模型
⑶ 假设
① 假设 1. Xi 未提供有关错误的任何信息
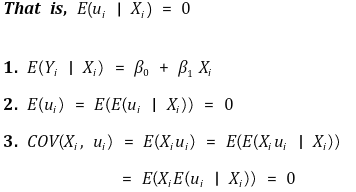
○ 如果残差图上有模式,则该模型不是好模型
② 假设 2. (Xi, yi) 是 i.i.d.
③ 假设3. 4阶矩的存在
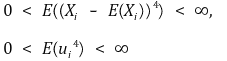
⑷ 拟合回归线的归纳 > ① 方法1. 矩估计器(MOM)或样本模拟估计的方法
○ 计算过程
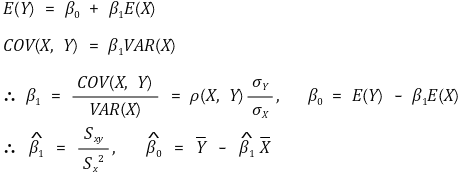
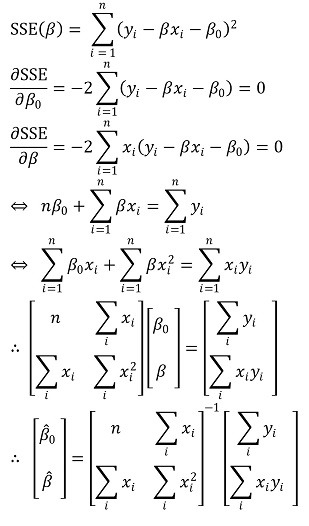
② 方法 2.最小二乘法或普通最小二乘法(OLS)
○ 定义:计算误差平方和的最小值(SSE)
○ 所有统计软件均提供
○ 计算过程 : 如果 Xi 是一维
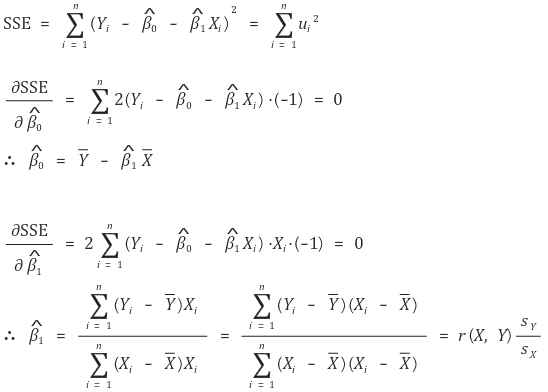
○ 最小二乘法基于最大似然估计(假设残差具有同方差性和正态性)

○ X到Y的回归和Y到X的回归一般不一样
○ E(X2), E(XY), E(X)等参与X到Y的回归
○ E(Y2)、E(XY)、E(Y)等参与Y到X的回归
○ E(X2), E(Y2), 等造成不对称
③ 方法3. 【交叉熵】(https://jb243.github.io/pages/2145)
○ 一般定义
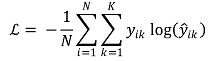
○ 二元分类
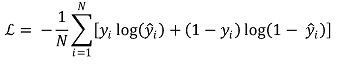
○ 如果 y 表示为 one-hot 向量 [0, ···, 1, ···, 0],则以下成立

⑸ 回归线的【特点】(https://jb243.github.io/pages/1630)
① 概述
② 公正性
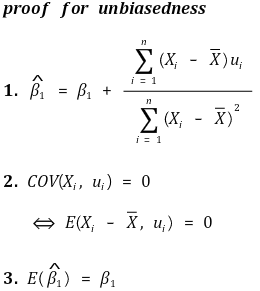
③ 效率
○ 高斯-马尔可夫定理: OLS 在满足同方差性时有效
④ 一致性

⑤ 渐近正态性
○ 坡度
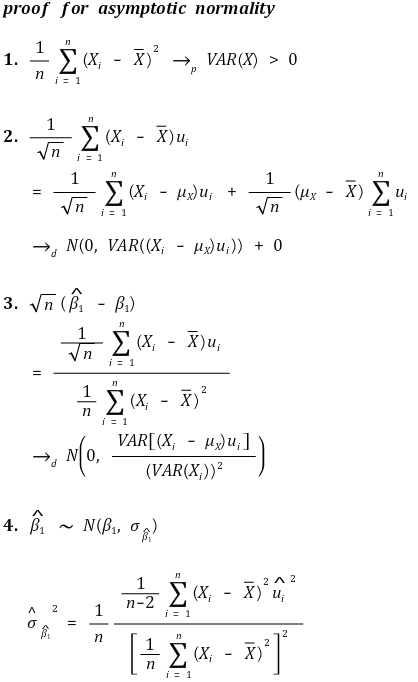
○ y 截距 - 异方差性 - 稳健标准误
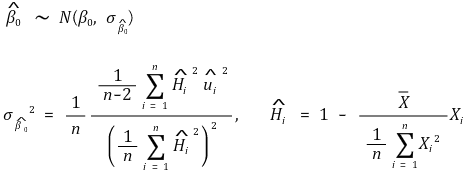
○ y 截距 - 同方差性-稳健标准误
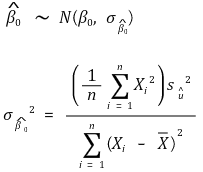
⑹ 回归线的评估
① 标准 1. 线性
② 标准 2. 同方差性 : 具有相等方差的残差项> ③ 标准 3. 正态性 : 遵循正态分布的残差项
○ Box-Cox : 在线性回归模型中难以假设正态性的情况下,此方法会将因变量转换为更接近正态分布。
⑺ 决定系数:也称为R平方
①决定系数R2
○ 定义
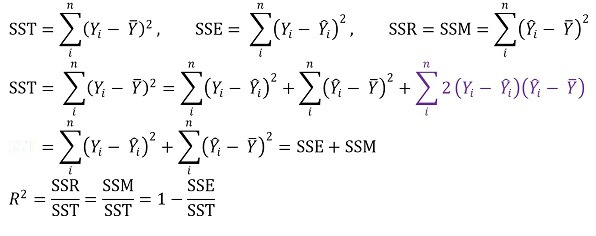
○ SST : 总变化
○ SSR : 回归方程的变化
○ SSE : 由于错误而发生变化
○ SSE也称为残差平方和(RSS)、残差平方和(SSR)
○ 术语 ■ 为 0** 的原因:** 因为偏差和机会误差的协方差直观上为 0
○ 含义
○ 含义 1. X可以描述的Y的方差比例(无单位)
○ 含义 2. 回归线描述的平方和 ÷ 总平方和
②决定系数与相关系数的平方相同
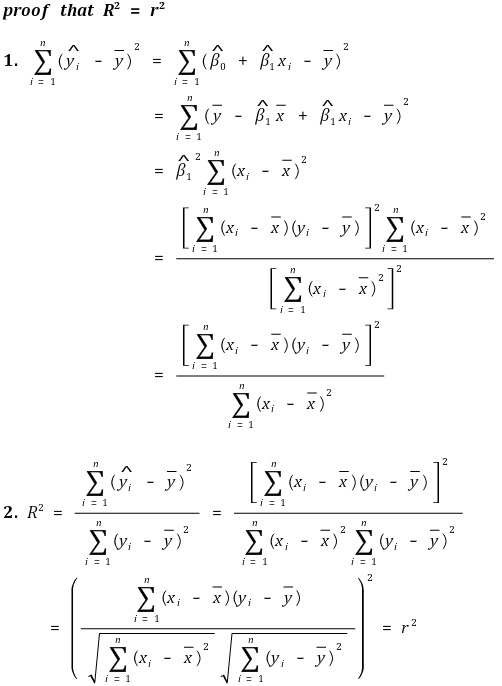
③ 无法解释的方差分数(FVU)
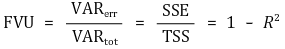
④ 特点
○ 0 ≤ R2 ≤ 1
○ R2越接近1,回归线的拟合优度越好
○ β1 = 0 的估计量 ⇒ R2 = 0
○ R2 = 0 ⇒ β1 = 0 或 Xi = 常数的估计量
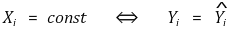
⑻平均误差回归
① 上证所公式
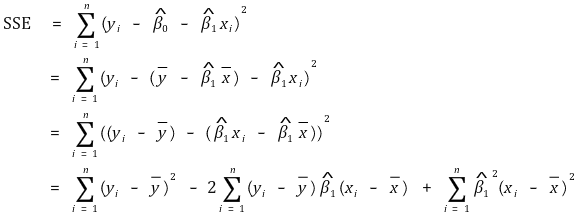
②上证所预期值
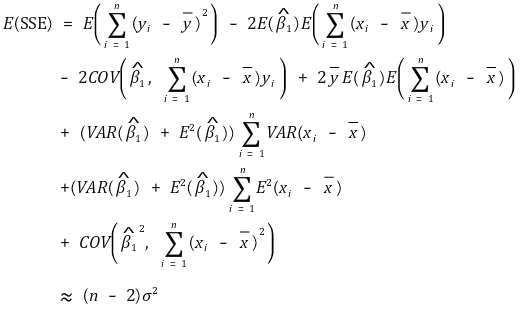
○ 总自由度 = 残差自由度 + 回归线自由度
○ 总自由度 = n-1
○ 回归线自由度 = 1 (∵ 只有一个回归变量)
○ 残差自由度 = n-2
③ 均方误差(MSE)
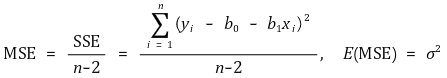
④ 标准误差回归(SER)
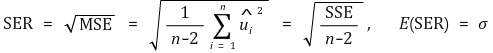
⑤ SSE 和无偏方差估计量
⑼ 例1. 回归的词源
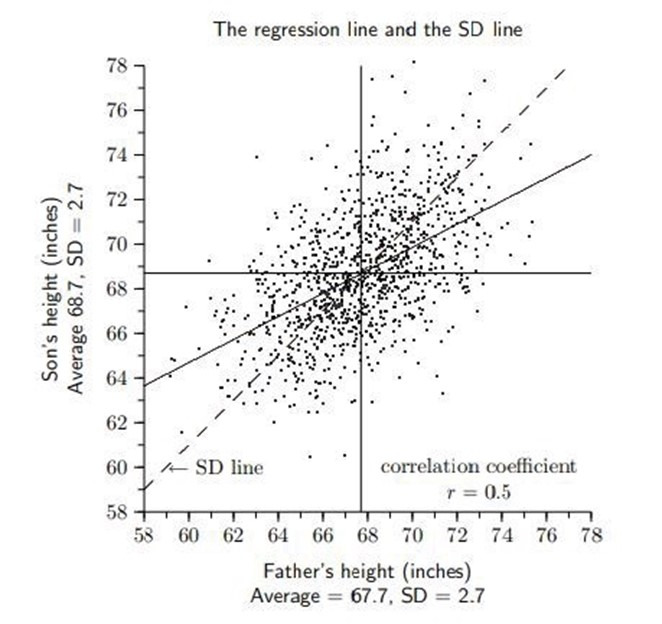
图 2. 回归的词源
① X : 父亲的身高
② Y :儿子的身高> ③ E(X) = 67.7, E(Y) = 68.7, σX = 2.7, σY = 2.7, ρXY = 0.5
④ E(Y | X = 80) = 74.85
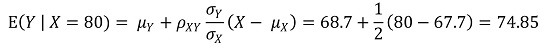
⑤ E(Y | X = 60) = 64.85
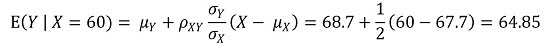
⑥结论
○ 高父亲的儿子往往会变矮
○ 父亲矮的儿子往往会长高
○ 儿子身高终于趋于平均水平
○ 然而,由于上述趋势仅基于期望值,因此儿子一代身高的方差不一定低于父亲一代身高的方差
⑽ 示例 2. 预测自变量范围之外的 Y 值:也称为外推法
①一般情况下不宜采用外推法

图 3. 外推问题
② 外推法并不总是错误的
○ 例子:生物进化研究
⑾【线性回归和二元正态分布的示例问题分布](https://blog.kakaocdn.net/dn/JMcdz/btsLJABUa7u/kWPry4j0RkcYiqBLKr2vM0/%E1%84%89%E1%85%A5%E1%86%AB% E1%84%92%E1%85%A7%E1%86%BC%E1%84%92%E1%85%AC%E1%84%80%E1%85%B1%2016%E1%84%8C%E1%85%A6.pdf?attach=1&knm=tfile.pdf)
⑿Python代码
来自 <span style=“color:#0e84b5; font-weight:bold”>sklearn</span> <span style=“color:#008800; font-weight:bold”>导入</span> Linear_model reg = Linear_model.LinearRegression() reg.fit([[0, 0], [1, 1],[2,2]],[0,1,2]) # 线性回归() reg.coef_ # 数组([0.5, 0.5]) </前></div>
## **3。多元线性回归模型** ⑴定义**:**多元回归分析的情况,其中相关性显示为线性函数 ⑵ 省略变量偏差 > ①定义**:**由于遗漏变量导致误差期望值不为零的现象
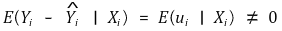
>> ○内生变量**:**与ui相关的变量 >> ○ 外生变量**:** 与 ui 不相关的变量 > ② **条件1.**省略的变量和回归量(_例如_,Xi)应该具有相关性 > ③ **条件** **2.**省略的变量应该是Y的决定因素> ④ 斜率的收敛值
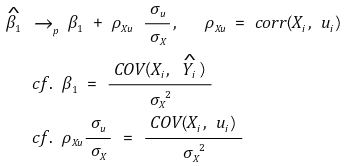
>> ○ ρXu > 0 **:** 向上偏压 >> ○ ρXu < 0 **:** downward bias > ⑤ 如果增加新变量时系数值变化较大,则可以说存在遗漏变量基础 ⑶ representation of data
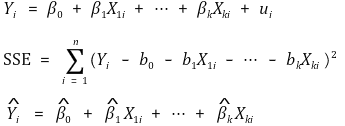
> ① 在上述估计量中观察到无偏性、一致性和渐近联合正态性 > ② 鲁棒性**:** 添加新的回归量不会显着改变回归量的任何斜率值的特性 > ③灵敏度**:**添加新的回归量会显着改变特定回归量的斜率值的特性 ⑷ 假设 > ① **假设** **1.** 错误不能由 X1i 解释,, ···, Xki > ② **假设** 2.** (X1i, ···, Xki,Yi) 是 i.i.d. > ③ **假设3.** 存在四阶矩
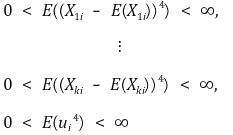
> ④ **假设 4.** 不存在完美多重共线性 >> ○ 多重共线性 **:**一个自变量与另一个自变量的线性组合高度相关的特征 >>> ○(注)多元线性回归模型期望自变量真正独立 >> ○ 完美多重共线性**:** 如果一个回归量与其他回归量具有完美线性。行列式值 = 0 >>> ○ 完美多重共线性不是变量的本质,而是数据集的本质
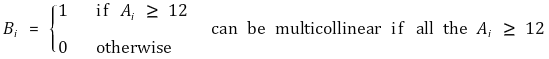
>>> ○ 当您尝试对完美多重共线性数据进行回归分析时,可能的系数数量是无限的**:** **不可能** 执行回归分析 >> ○ 不完美多重共线性 **:** 两个或多个回归变量只是高度相关 >>> ○ 立刻不是问题 >>> ○ 斜率估计器的方差相当大 → 难以信任斜率估计器
图4.多重共线性增加斜率估计量方差的原因 ⒝ 显着性区间内可能存在多种平面
>>> ○ 一般来说,一对变量的相关性不应超过0.9 >> ○ 解决方案 >>> ○ 绘制所有组合的成对图并删除高度相关的变量 >>> ○ PCA、加权和等可以尝试,但各有各的缺点 >> ○(注)R Studio 在分析完美多重共线性数据时随机忽略最后一个有问题的项 ⑸ OLS估计器**:**通过计算以下联立方程来确定系数
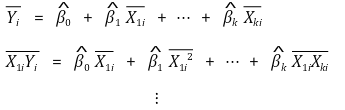
⑹ 回归线的特点
> ① 公正性 > ②一致性 > ③渐近联合正态性 > ④ 弗里希-沃定理

⑺调整R2 > ①R2的缺点 **:**拟合程度在多元回归模型中没有得到很好的体现 >> ○ **缺点 1.** 每当添加新的回归量时,R2 总是会增加,因为 SSE 的最小值会减小 >> ○ **缺点 2.** 高 R2 无法验证是否存在遗漏变量偏差 >> ○ **缺点 3****.** 高 R2 不能验证当前回归器是否最优 >> ○ 为解决**缺点1**,引入调整后的R2 > ② 公式
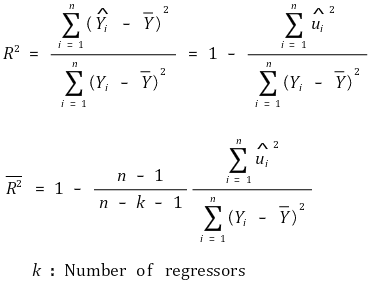
> ③特点 >> ○ 调整后的 R2 ≤ R2 >> ○ 调整后的 R2 可以为负值 >> ○ 添加不适当的变量后,值会减小 ⑻ 标准误差回归(SER)**:** k 为回归方程中自变量的数量
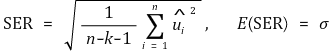
⑼ 联合假设**:**当存在大于或等于2个约束条件时的假设 > ① **想法 1.** t1 和 t2 是独立的
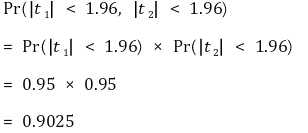
② **想法2.** t1 和 t2 存在多重共线性
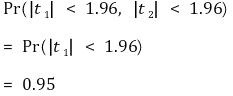
> ③一般情况

>> ○ 一般情况下,使用异方差稳健 F 统计量 >> ○ 许多统计程序都将同方差稳健 F 统计量作为默认设置 > ④原假设
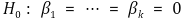
⑽ 多元线性回归模型的重新定义
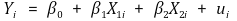
> ① H0 **:** 如果要测试 β1 = β2,
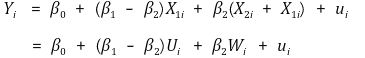
> ② H0 **:** 如果要测试 β1 + β2 = 1,
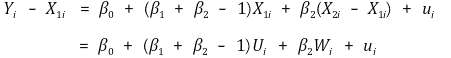
⑾ 条件平均独立性 > ①定义
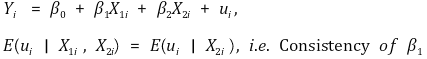
> ② 对于给定的 X2i,X1i 与 ui 不相关 > ③ β2 可能不具有一致性**:** 但这并不重要 ⑿ 矩阵表示法 > ①线性回归模型>> ○ 对于标量 Y、列向量 X 和 β,
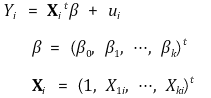
>> ○ 概括
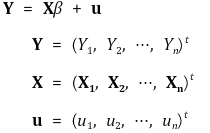
> ②假设 >> ○ **假设 1.** E(ui | Xi) = 0 >> ○ **假设 2.** (Xi, Yi), i = 1, ···, n 为 i.i.d. >> ○ **假设 3.** Xi 和 ui 具有非零有限四阶矩 >> ○ **假设** **4.** 0 < E(XiXit) < ∞,不存在完美多重共线性 > ③ OLS建模-简单版
> ④ OLS建模
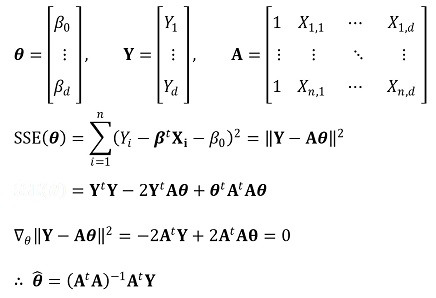
> ⑤ 一致性
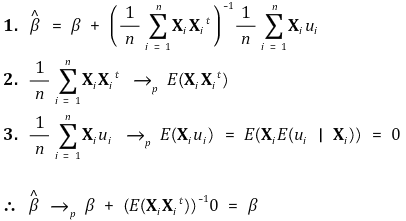
> ⑥多元中心极限定理
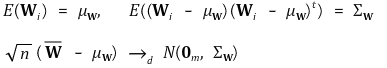
> ⑦ 渐近正态性
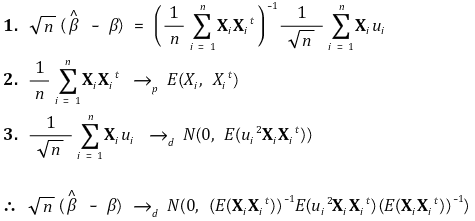
> ⑧ 鲁棒标准误(Eicker-Huber-White 标准误)
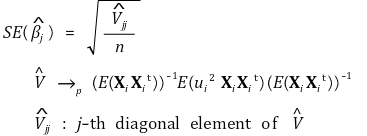
> ⑨ 稳健的F
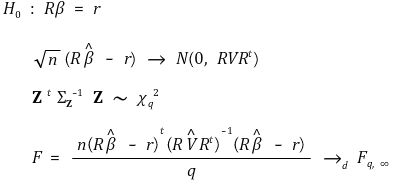
--- *输入:2019.06.20 23:26*